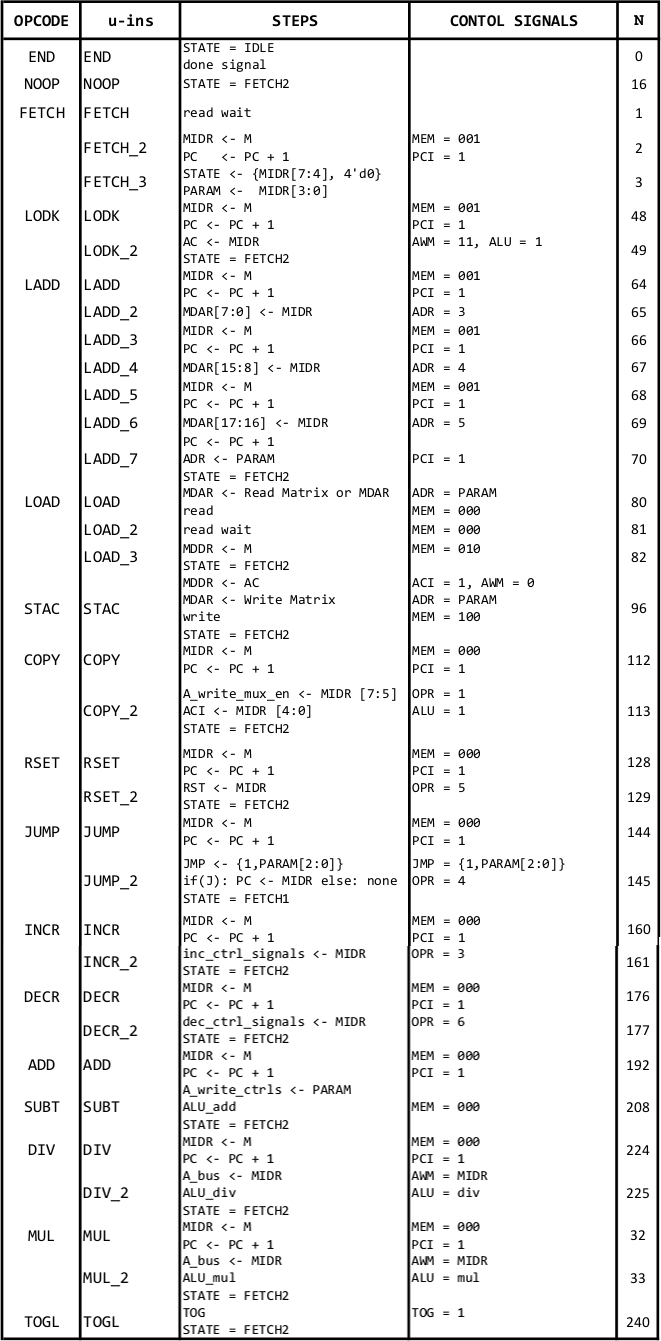
Custom Processor (Verilog), ISA, Compiler & Simulator (Python)
The major challenge in designing a processor is the trade-off between the size of ISA, hardware complexity and user-friendliness. ABRUTECH is a unique custom processor highly optimized to manipulate matrices while preserving the functionalities of a generic processor. It has been designed to strike the delicate balance in the above tradeoffs. While having only 16 instructions, the ISA of ABRUTECH is crafted to be simple, yet highly powerful and is implemented using only 1000 logic elements.
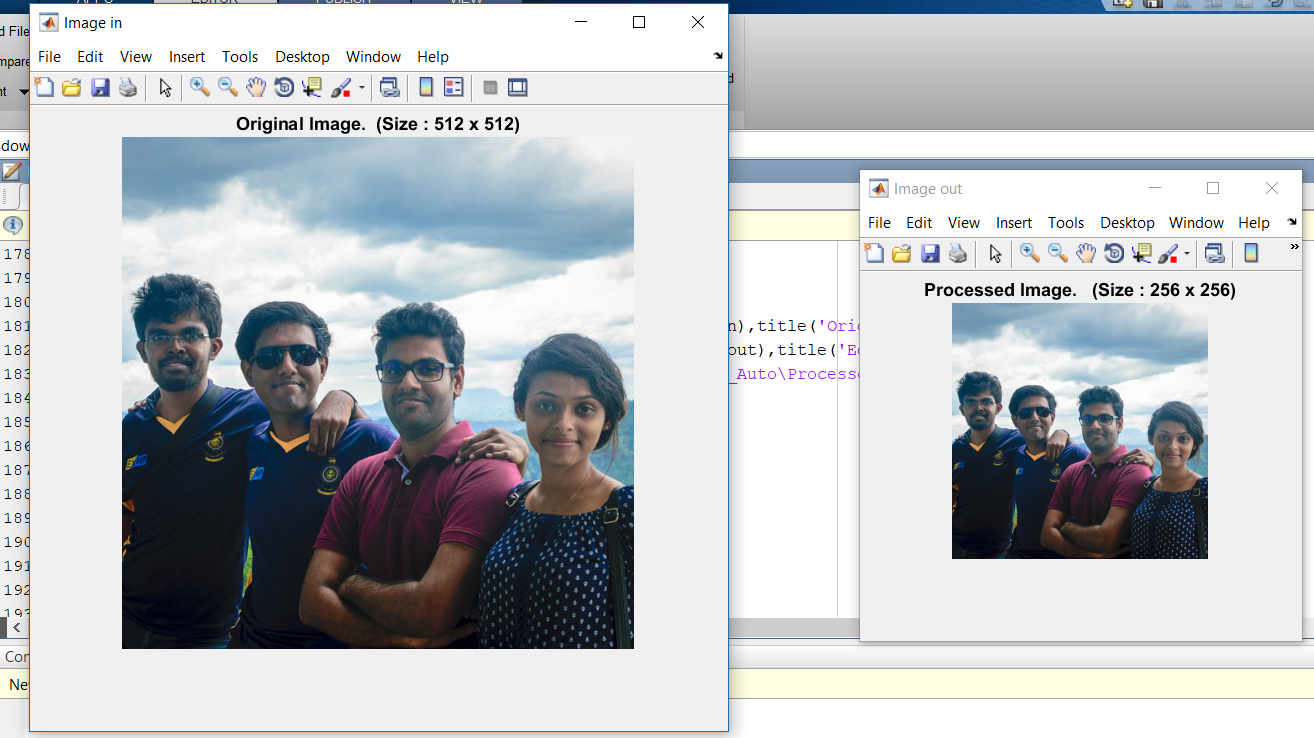
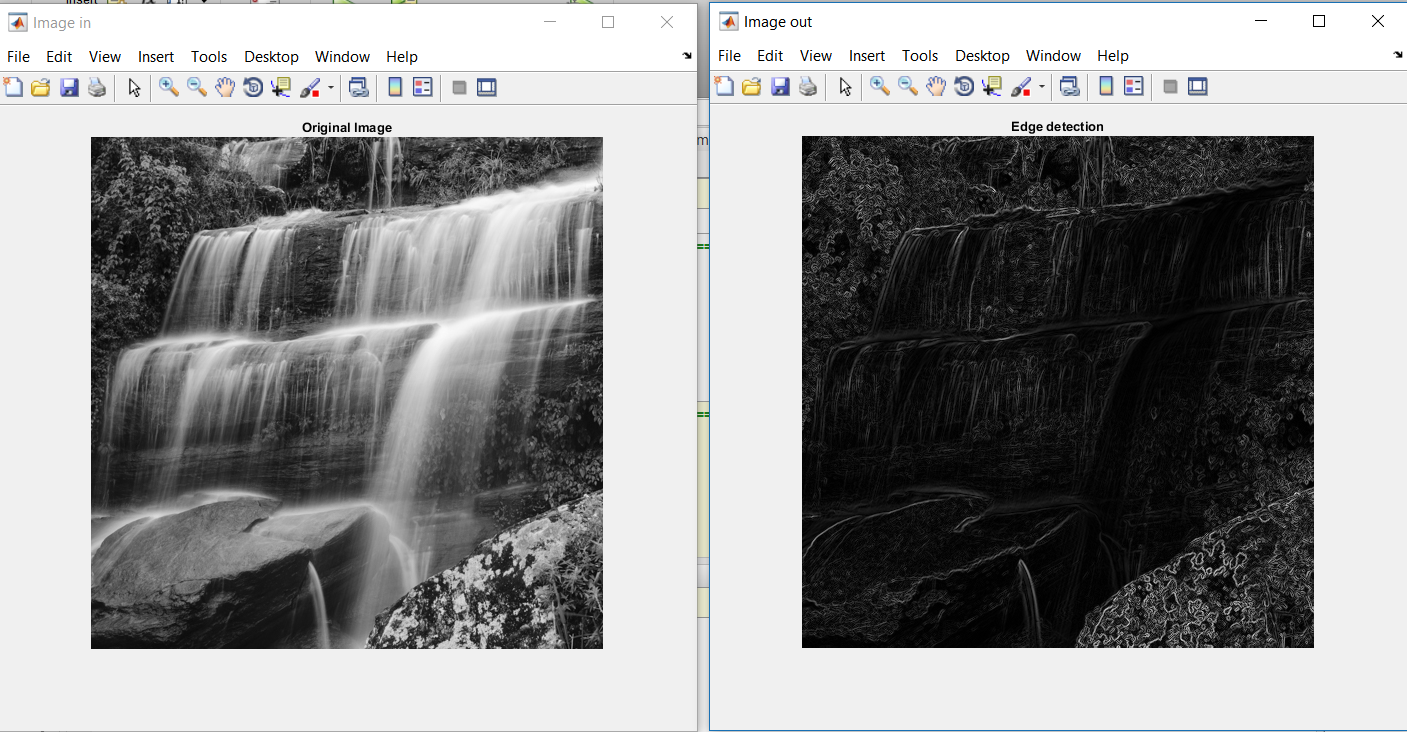
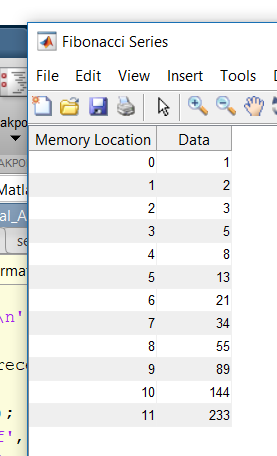
This is demonstrated in the results section, with sample programs that are only 30-40 bytes long but are able to downsample and upsample any 512x512 image by any integer, detect edges, find prime numbers and Fibonacci numbers. . . etc.
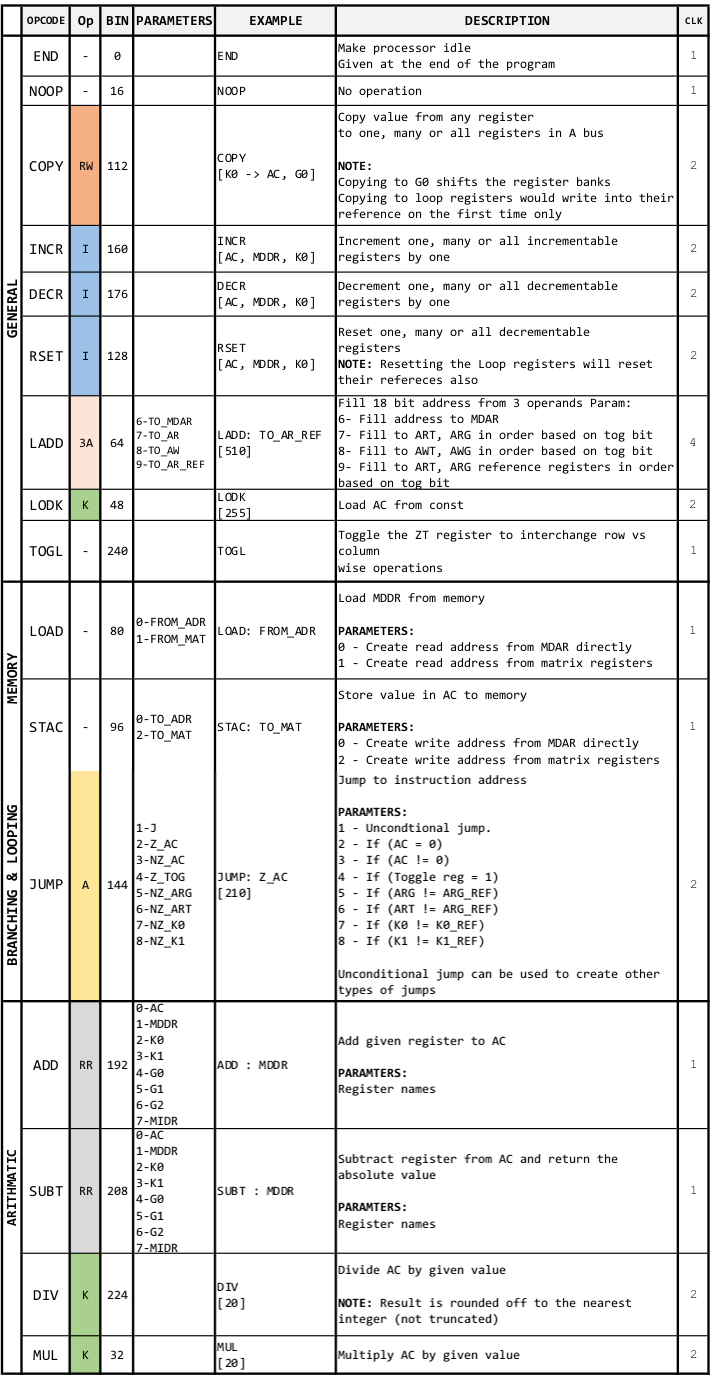
Instruction Set Architecture (ISA)
With only 16 instructions each of which execute in only 2.2 clocks cycles on average, our ISA and the complier allow the programmer to write programs quickly that take only 1.8 bytes of memory per instruction on average. Our ISA was designed to incorporate advantageous features from both RISC and CISC instruction sets. As in RISC, each operation is designed to perform a specific task, especially the load and store operations are maintained strictly separate. However, unlike RISC, not all instructions are of equal length but are either 1, 2 or 4 bytes long. Certain instructions are encoded, resulting in high code density. This allows building smaller programs that use the limited instruction memory efficiently while also allowing faster execution. However, this is balanced with maintaining moderate hardware-level complexity in our system architecture.

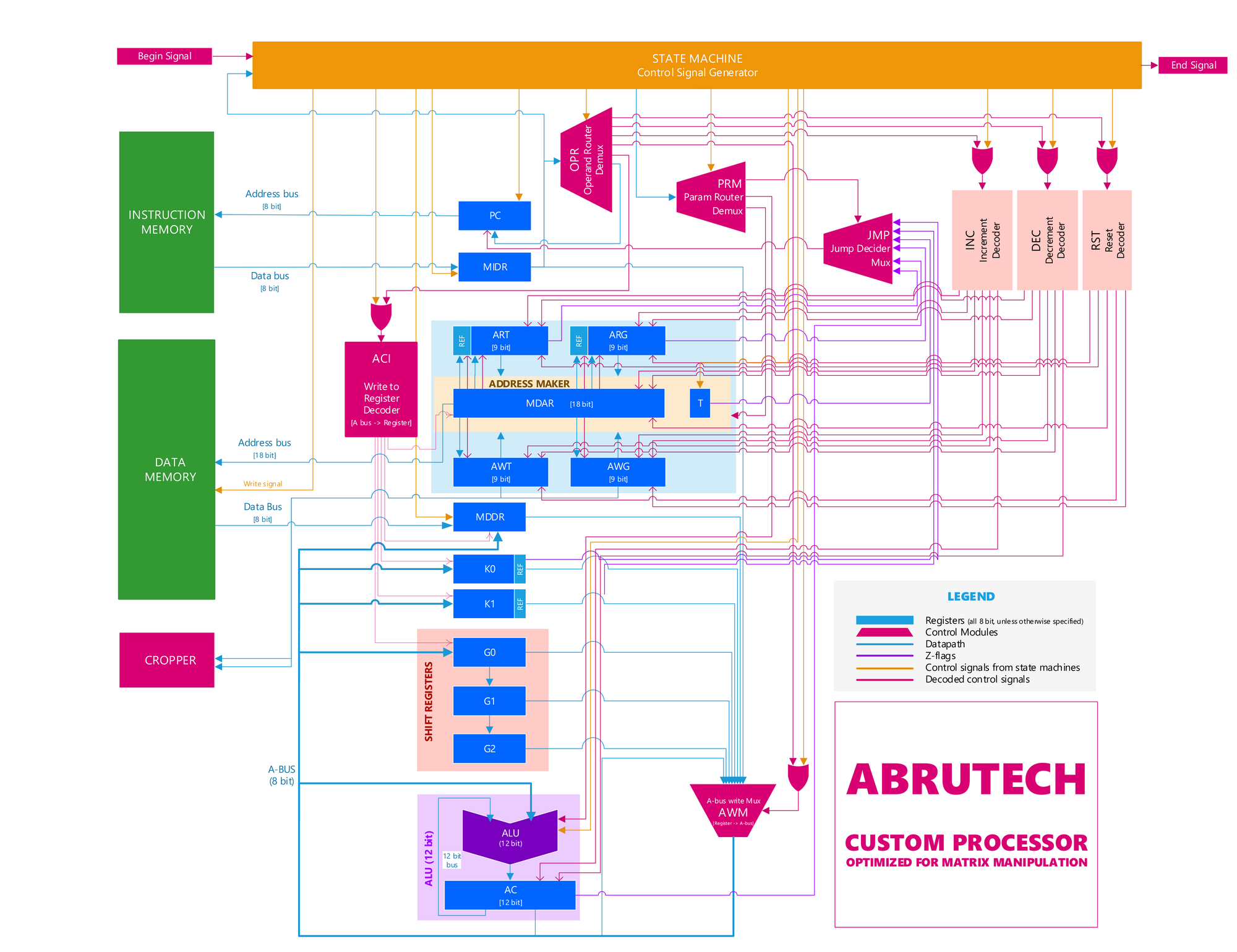
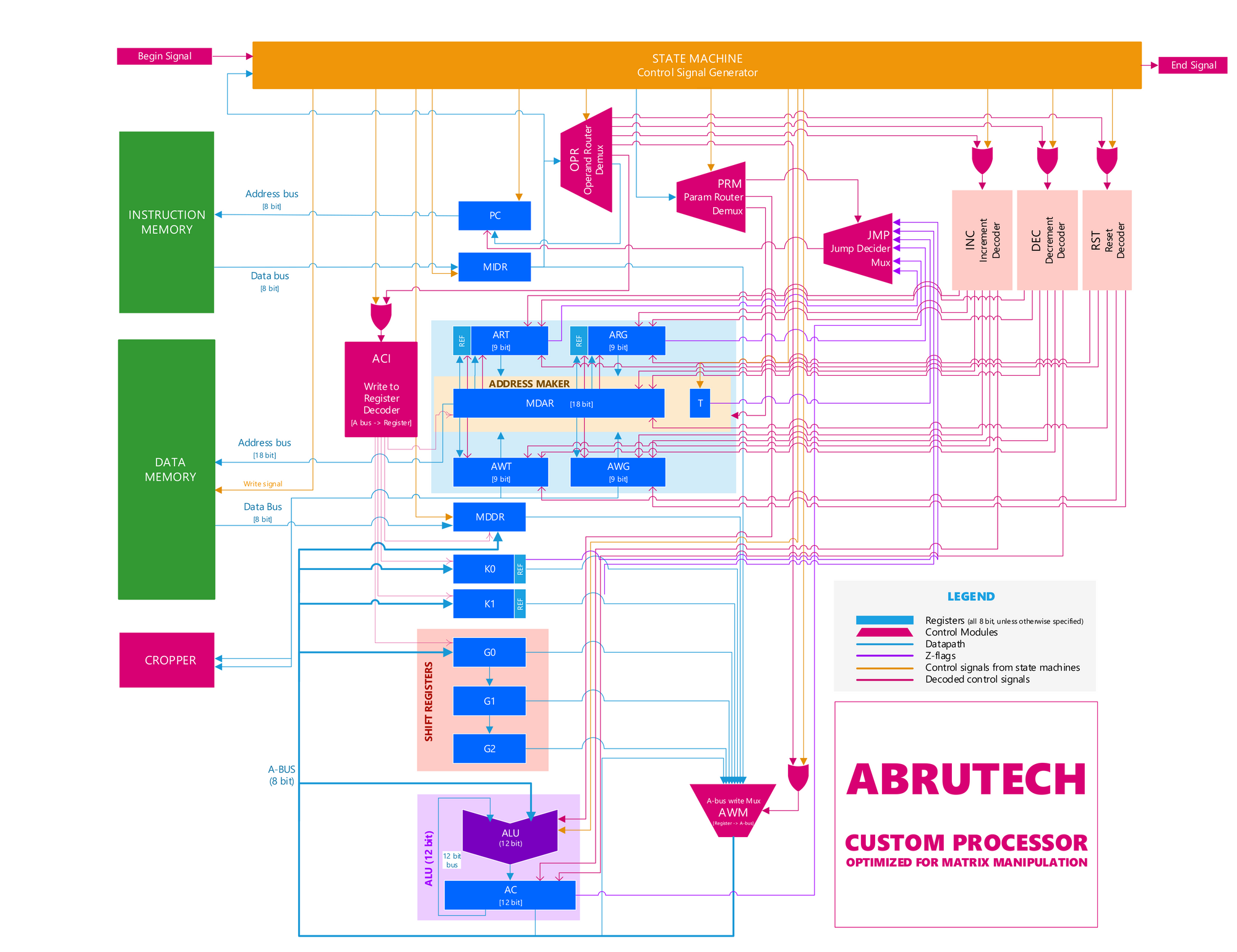
Architecture
ABRUTECH works with an 8-bit wide, 262144-bit (512x512) deep data memory and an 8-bit wide 256-bit deep instruction memory, both of which can be loaded through UART. The system was coded in Verilog HDL using Intel Quartus II Prime and implemented successfully on an Altera de2-115 development board.
While being an 8-bit processor, (bus sizes and most register sizes being 8-bit), ABRUTECH features a 12-bit ALU and accumulator, which allows it to process calculations with intermediate steps that give results up to 4096, without causing an overflow error. The ALU is also designed to perform round-o divisions (unlike the typical our division), to improve accuracy.
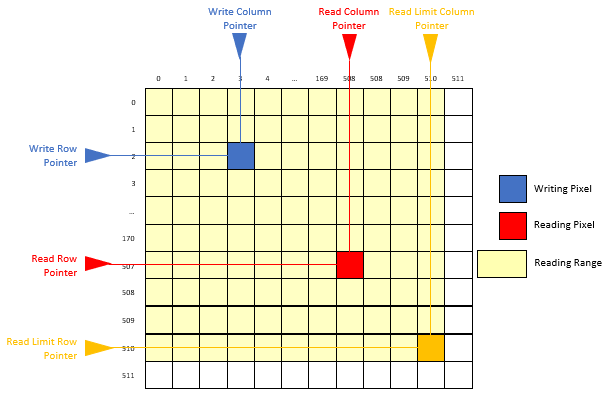
Our processor also features a special module called Address Maker, which (optionally) allows the programmer to navigate a 512 x 512 matrix either row-wise or column-wise, without the need of a complex algorithm. This helps in implementing image processing algorithms such as downsampling, nearest neighbour upsampling, upsampling by bilinear interpolation.
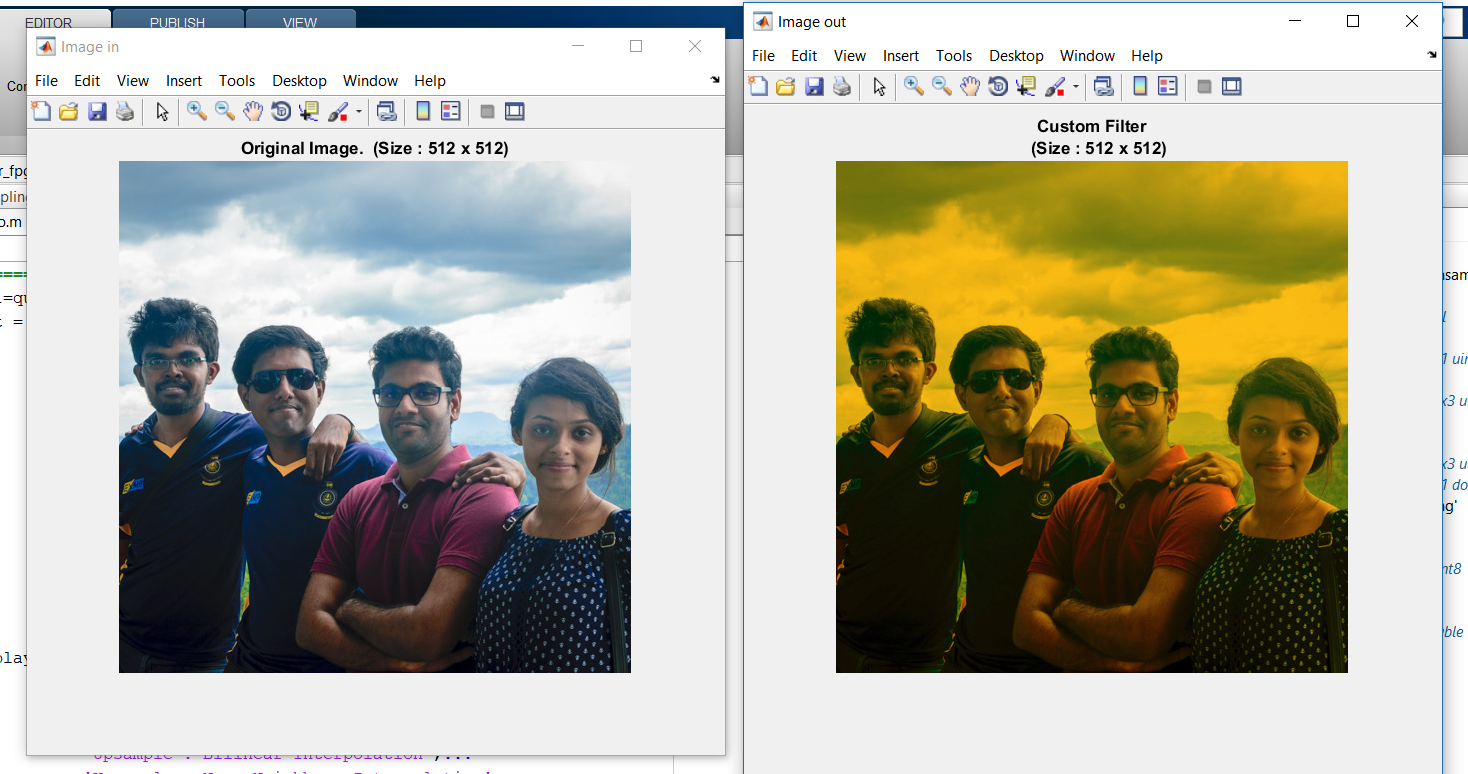
Another special feature in ABRUTECH is a bank of shift registers, which help to perform linear convolution operations several times faster. Together with Address Maker, this allows the programmer to perform 2D convolution with a linearly decomposable kernel, such as Gaussian smoothing or edge detection, without losing a row and a column of data in the process, as with the traditional algorithms.
Compiler & Simulator in Python (Aba)
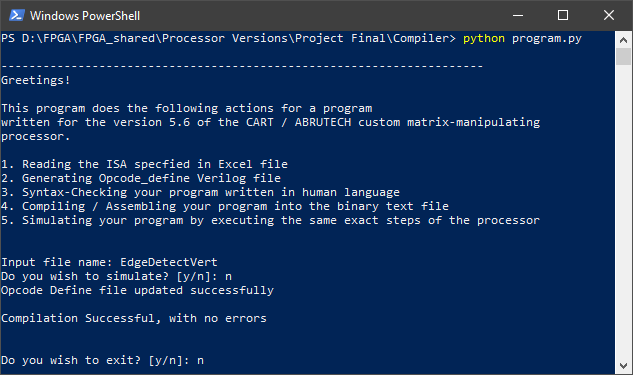
I also built a corresponding python-based compiler program, which scans the excel sheet where ISA is specified and translates the algorithm written in the human language to an array of binary values, which are then sent to the instruction memory through UART. The compiler identifies syntax errors, which allows the programmer to write assembly code with ease, using our ISA.
In addition to the compiler, I built a simulator software for ABRUTECH. The simulator can run the algorithm like the processor and show the values of registers and memory at each step, helping us debug an algorithm fast and remotely, without repeatedly loading it into the processor.

Algorithms
As detailed in the report, we devised brand new algorithms for downsampling and other tasks, which are mathematically justified (in the report) to have better accuracy and speed than traditional algorithms.









Hardware Debugging
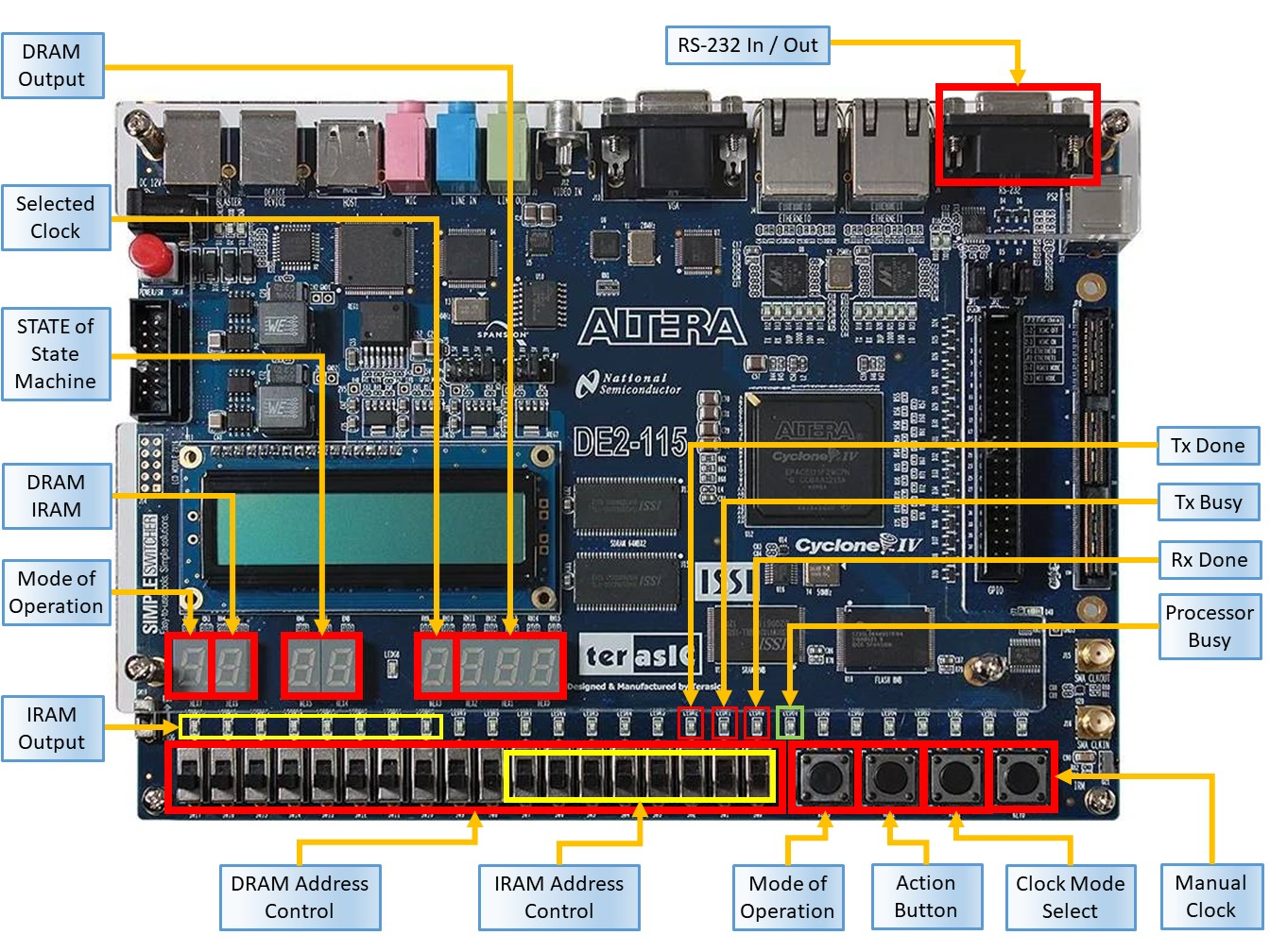
The system itself is implemented with hardware debugging features, such as the ability to run the processor either at 1 Hz clock frequency, 10 MHz clock frequency or through a manual clock provided by a push-button. We are able to see the currently fetched instruction and currently retrieved data on 7 segment displays and LED bulbs.
Our processor is also free of major hardware vulnerabilities, such as spectre and meltdown since we did not have the time to implement the branch prediction and speculative execution modules. :-)
Results