Vision-Based Adaptive Traffic Control on an MPSoC [ARM+FPGA]

Overview
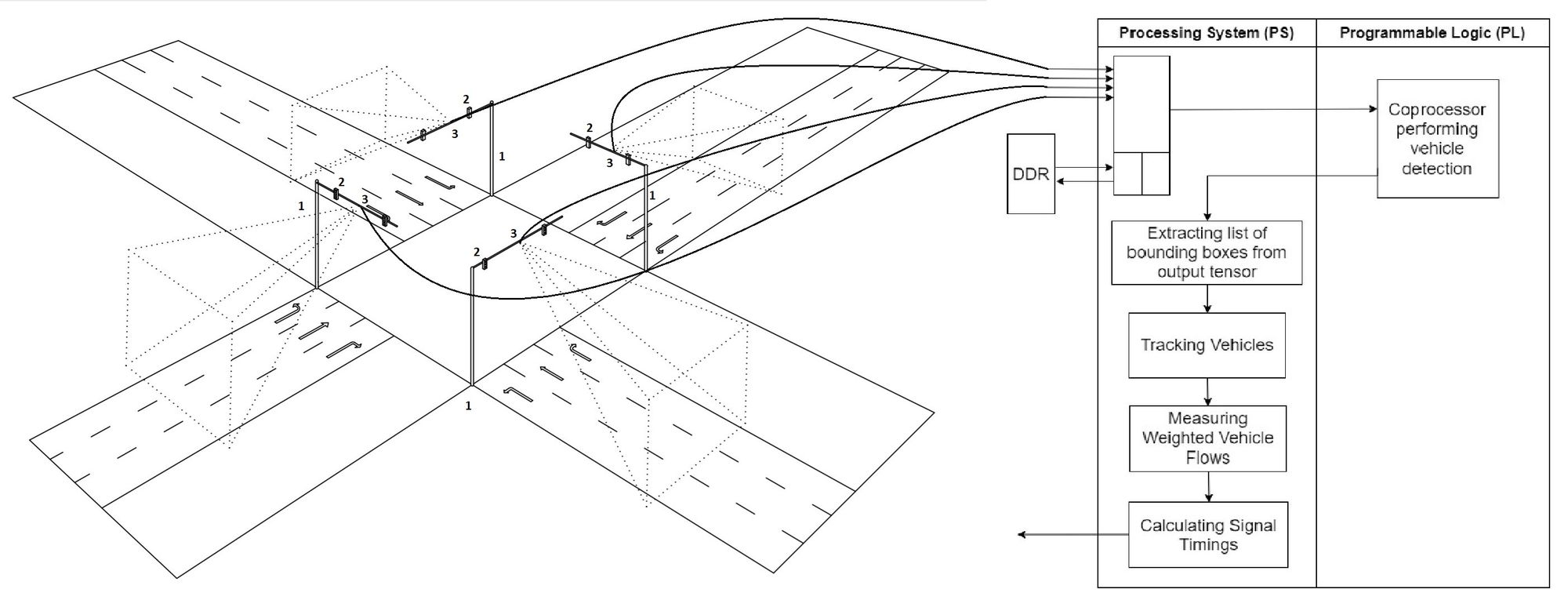
As a modular, mass-manufacturable and decentralized edge solution to the adaptive traffic control problem, we designed and implemented a custom CNN accelerator on FPGA, modified & trained YOLOv2 object detector with custom Sri Lankan data to detect vehicles in the day, night & rain, and wrote custom algorithms to track vehicles, measure weighted critical flow with 100% (day) & 80% (night) accuracy, and calculate traffic green times (delta algorithm) on the ARM processor core.
A patent for our system is currently under review at NIPO and the system is being further developed with funding from World Bank via AHEAD into a product by a multidisciplinary team of engineers through the Enterprise (Business Linkage Cell) of the University of Moratuwa, together with RDA and SD&CC.
It's storytime... How it started:
In my 3rd year (5th semester), by pure chance, we formed a team of four: Abrutech (Abarajithan, Rukshan, Tehara, Chinthana) for our processor project. Soon we figured out that we had great chemistry, we complemented each other's strengths and weaknesses, a team made in heaven. :-)
 Abarajithan G
Abarajithan G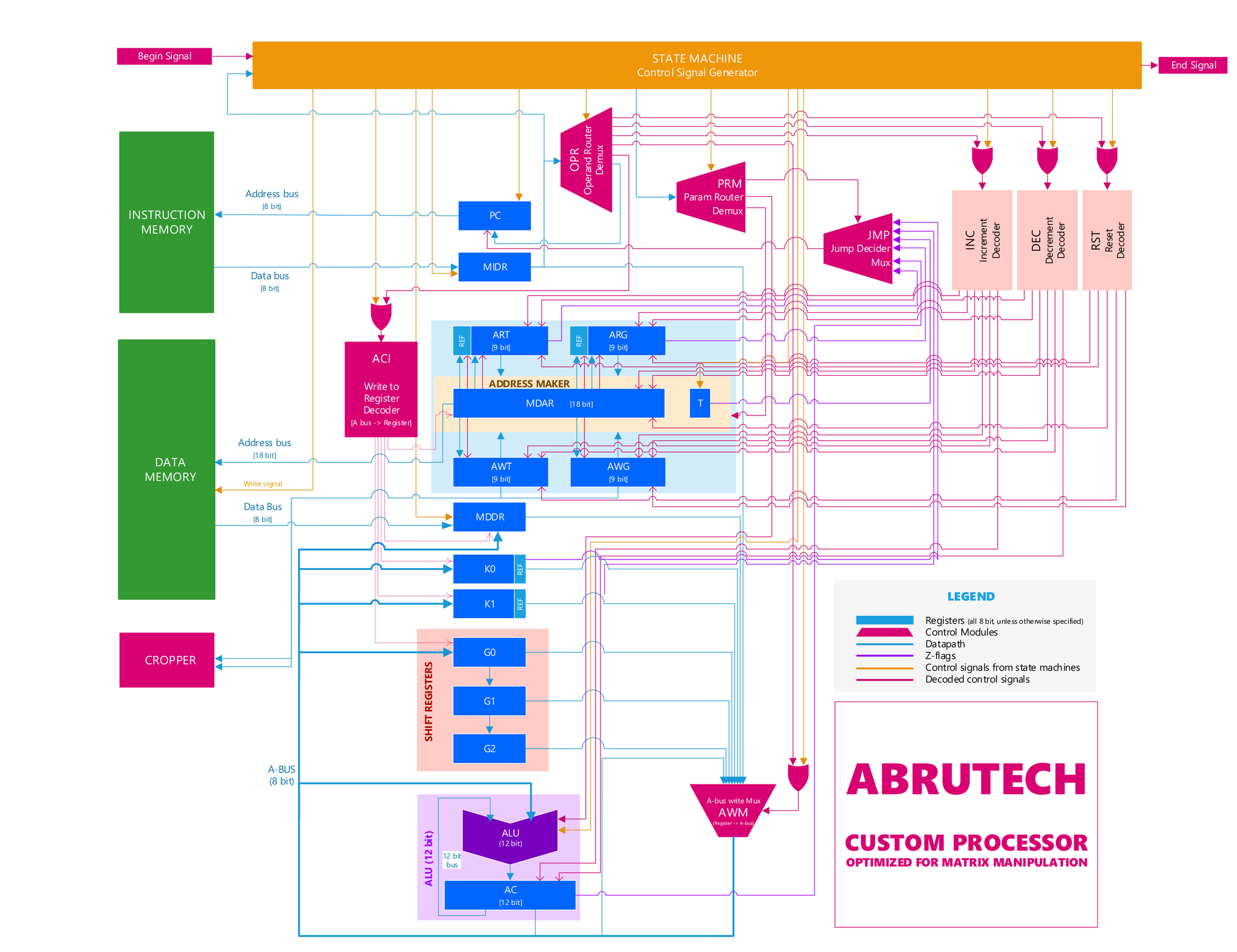
I had a knack for digital architecture design and I was good at coming up with ideas and algorithms. Rukshan was the best verification engineer I have seen. With infinite patience and thoroughness, he never skipped a corner case. A Verilog module he wrote and tested is as good as formally verified. Tehara had the passion and patience to modify neural networks and train them for weeks. Chinthana was the street smart guy, the jack-of-all-trades, who could learn and do any task within hours.
By the end of that project, I had decided that I want this group forever, especially for the final year project. Also, the feeling I got when I designed architecture was nothing but pure bliss. It was addictive, I had never felt that before. I was in love.
In the next semester, we all started our internships. At CSIRO (Australia), as I worked with building CNNs on Tensorflow/Keras, training them and implementing them on edge devices (Jetson TX2), I itched to design an architecture to accelerate complex CNNs, such as object detectors. That was a perfect idea for our team. Rukshan was implementing a Maxpool engine for a simpler CNN at NTU (Singapore), Chinthana was building a python compiler for ML on ASIC at Wave Computing and Tehera was working object detectors (RCNNs) at Zone 24x7. So, we collectively decided on this topic and were brainstorming remotely from three countries.
Abarajithan G
However, when we proposed the idea to a few scientists at CSIRO and lecturers in our department, they suggested that an FPGA implementation of a custom CNN engine would be a waste of time, as GPU-based systems are the popular ones for inference back then, and that we will not be able to publish this. Disheartened, we searched for a staff-proposed project where this solution might make sense. We found Prof. Rohan's project, funded by the world bank, titled Vision-Based Traffic Control. It was a topic that was attempted a few times in the past and failed. One team had tried to fly hot air balloons, another MSc team tried a simpler approach with Raspberry Pi, of passing the images through an edge-detection kernel, counting white pixels and using a custom fully-connected network of 2 layers trained on a custom dataset of few hundred images to estimate a traffic level (1-5) from the white pixel count.
We proposed to tackle this problem with our own mass-manufacturable, robust solution. A pre-trained and then fine-tuned object detector running on our custom engine in an FPGA and a custom algorithm tested in VISSIM simulations to control the traffic lights based on those detections. This received a huge backlash from some staff members, who pointed out a few valid concerns. We may not have enough time to obtain government permission to demonstrate this on the road, and the CNNs may not work with Sri Lankan data. After some traumatizing back and forth via academic politics, we picked the project in February.
As a response to "Like everyone, you will start collecting data way too late... in August, and find your model doesn't work", I vowed to demonstrate it within ten days! Rukshan built a data collection device, powered by a power bank through a 40-feet wire and programmed a python GUI to control its 2-axis servo and camera via Wi-Fi. We collected 750 images, Tehara ran pretrained YOLOv2 on them and we showed that we can detect ALL vehicles in both day and night time, acing the feasibility presentation within 10 days. With that start, we were good to go.
Methodology
The loop detectors and radar-based traffic sensing methods lacked accuracy, especially for smaller vehicles like motorcycles, which jam the traffic in developing countries. Vision-based adaptive controls in developing countries primarily rely on processing in a central server, which requires a high s setup cost. Research level edge solutions based on processors use simple algorithms (like edge detection) and aren't robust enough in different lighting conditions. Ones that run on GPU-like systems aren't mass manufacturable. Therefore, we came to the conclusion that our method of a state-of-the-art, robust object detector accelerated on a mass-manufacturable FPGA-based system best solves all these issues.

1. Machine Learning
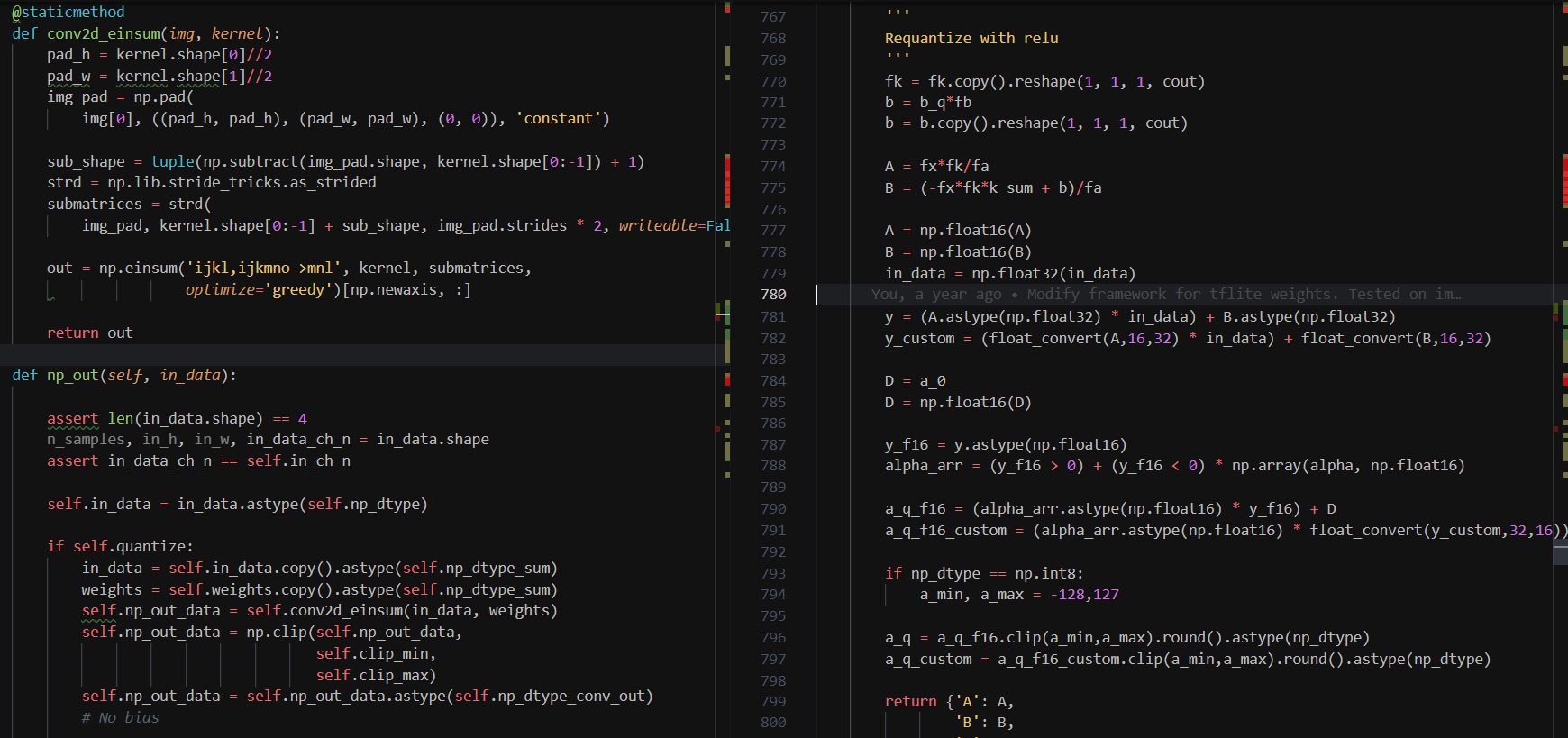
1.1 Inference Framework for Precision Experiments (Aba)
I built a Keras-like object-oriented inference framework using the multidimensional operations of NumPy. Layer types (Conv, Relu...etc) are implemented as subclasses of the common Layer class. They can be chained to build a model, which can forward propagate an image through multiple datapaths.
 262588213843476
262588213843476
1.2 Data Collection Devices (Rukshan, Chinthana) & Annotation (Tehara)
Built four remotely powered, wirelessly data-collection devices. Collected, annotated and augment traffic images to create a Sri Lankan traffic dataset (1500 images).

1.3 CNN Architecture & Training (Tehara)
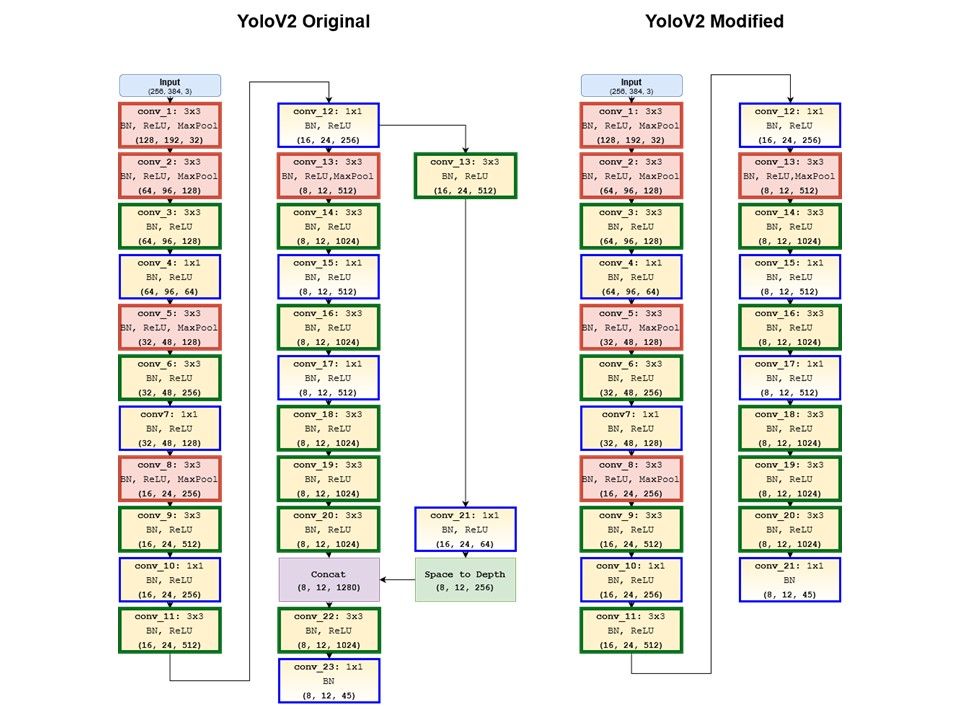
Optimized the architecture of the YOLOv2 object detection neural network for hardware implementation. Trained YOLOv2 and TinyYOLO.
- Fused batch normalization into convolution by modifying the weights and biases accordingly.
- Interchanged conv => leaky-relu => max-pool to conv => max-pool => leaky-relu to reduce power.
- Changed the output layer from 80 classes to 5 classes, by reusing weights of appropriate classes.
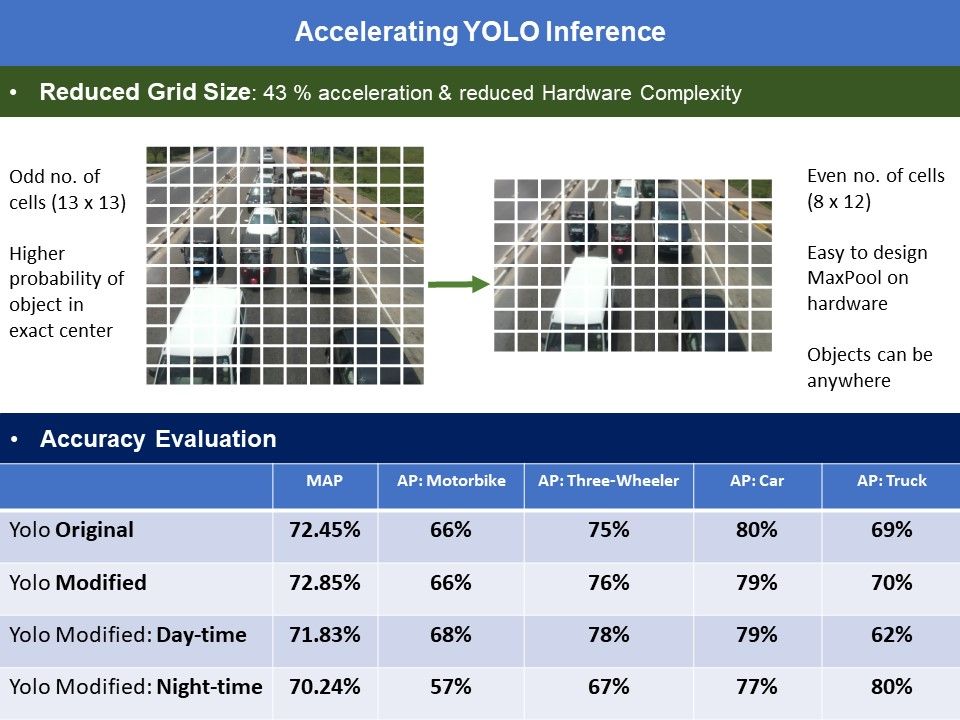
- Changed grid size from (13 x 13) to (12 x 8) and designed the sensing algorithm accordingly
- Trained with custom Sri Lankan Traffic Dataset (three-wheelers)


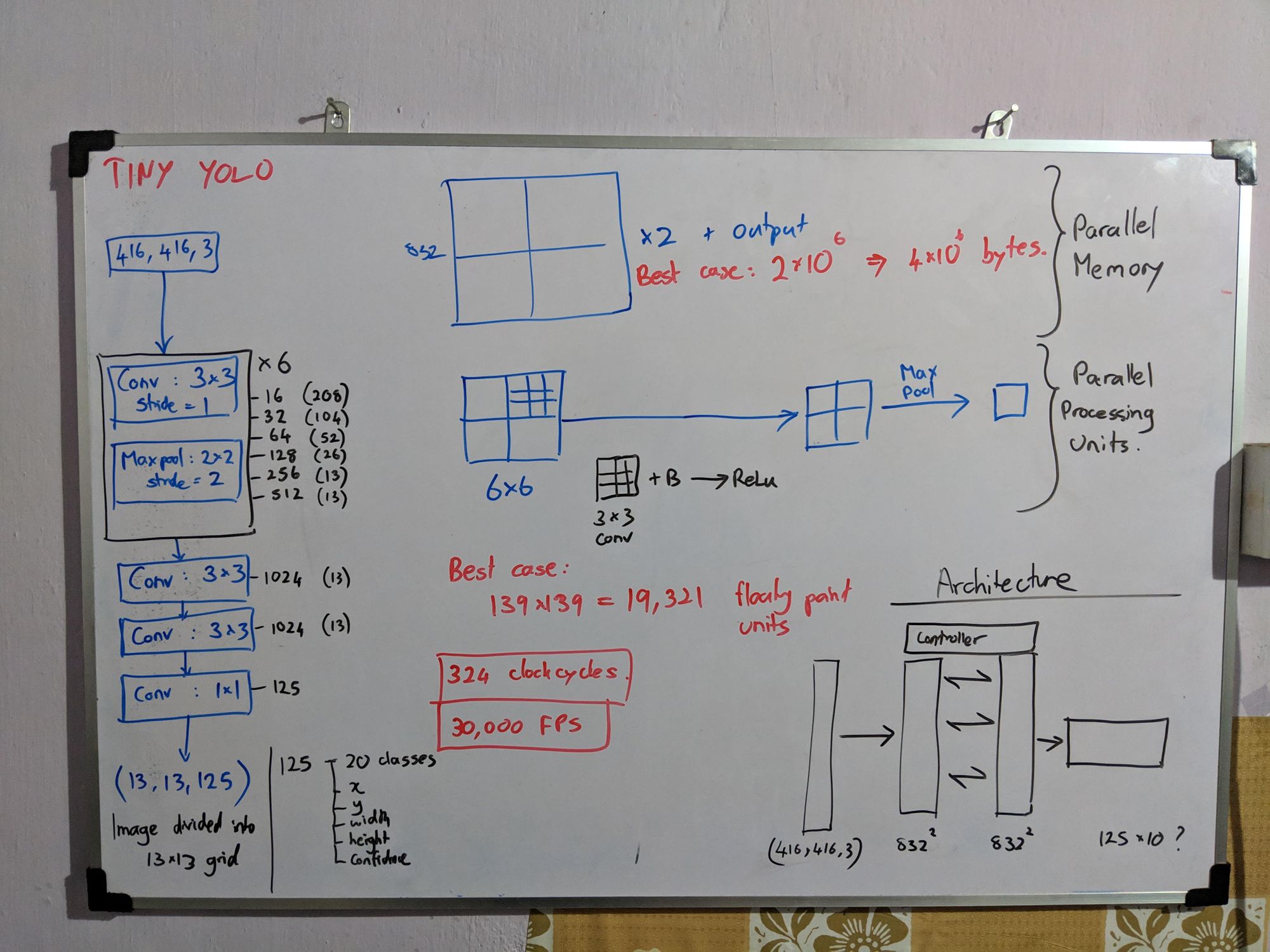
2. CNN Accelerator Design (Aba)
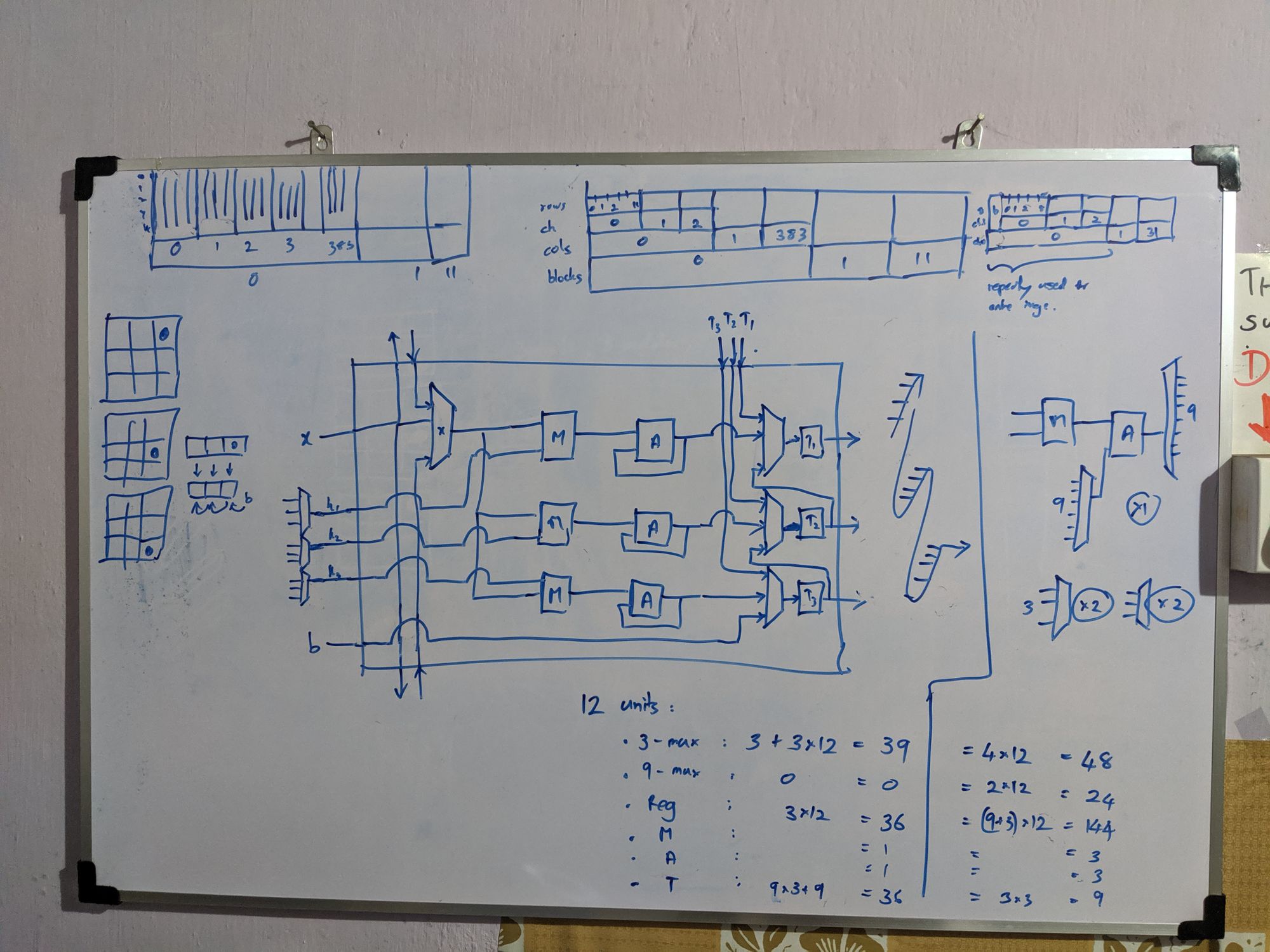
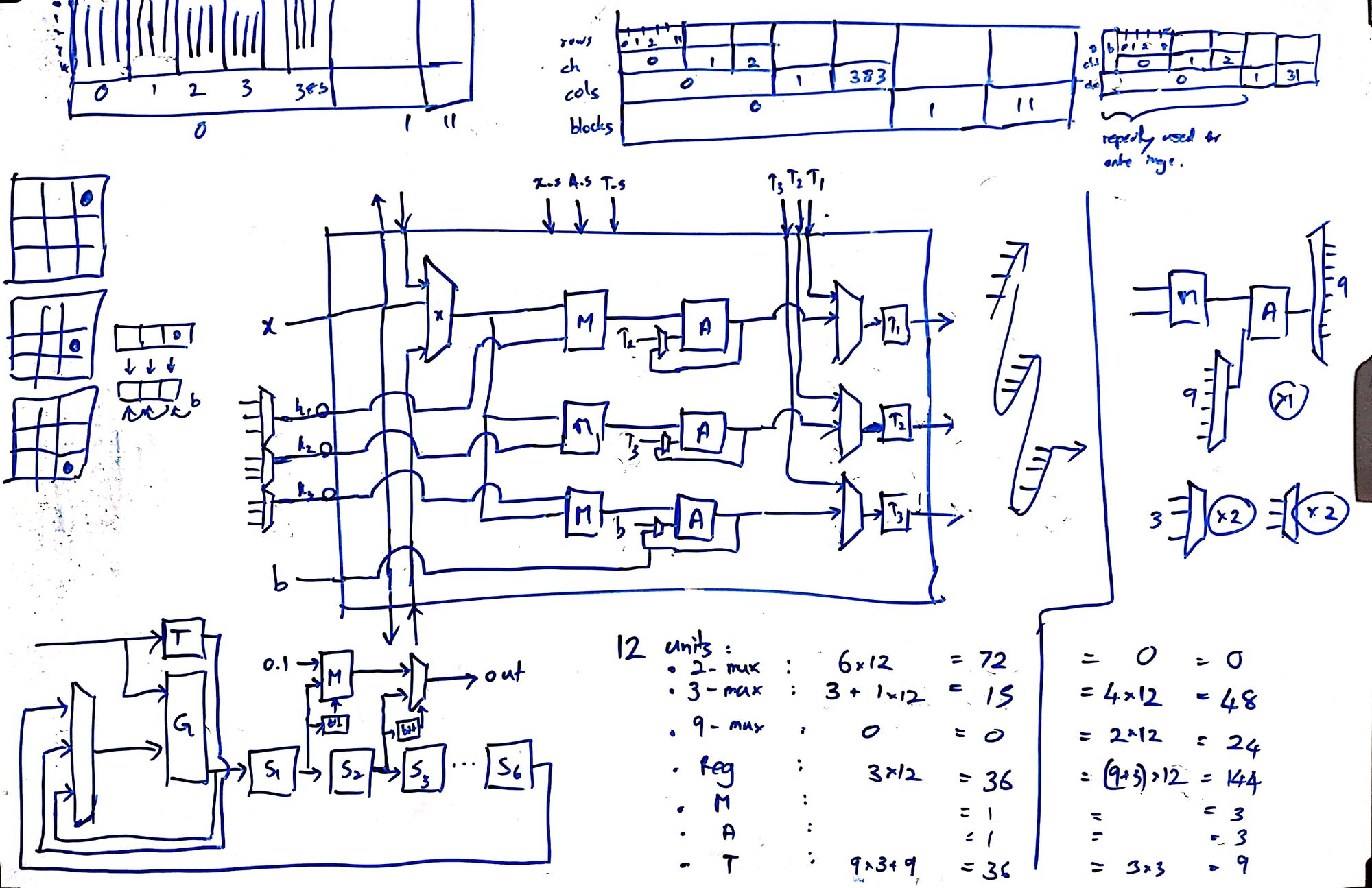
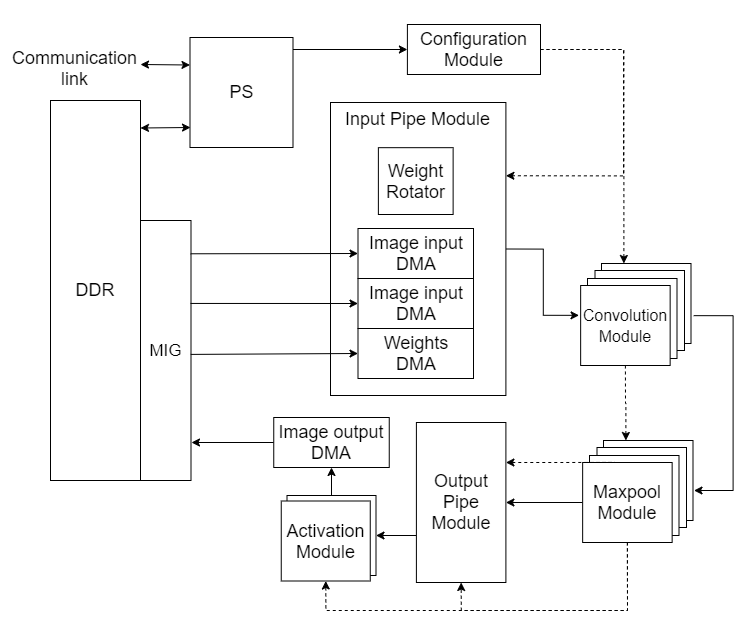
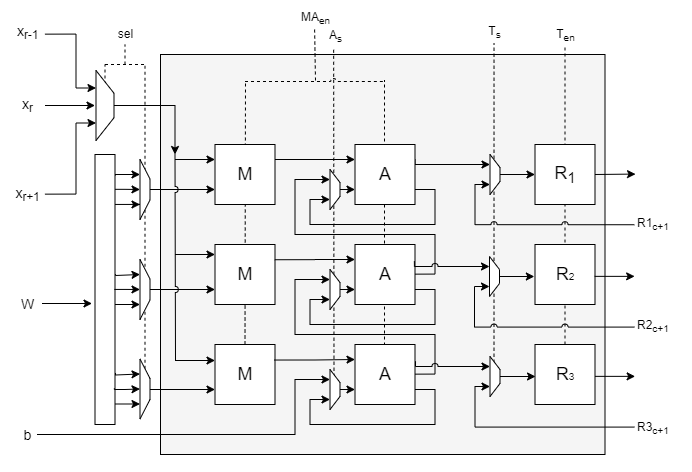
I designed our first engine, which in retrospect resembled ShiDianNao (ISCA’15). With 9-muxes x 24, 3-muxes x 48, 16-bit registers x 144, multipliers x 3, accumulators x 3, each core, performed 12 of 3x3 convolutions in 9 clock cycles. Rukshan implemented it and demonstrated it in simulation. But we couldn't fit enough processing elements of it in our FPGA to run YOLOv2 at any respectable speed. The LUT count exceeded, thanks to large 9-way multiplexers. Several registers stayed unused over most clocks. In addition, Rukshan hated the ad-hoc solutions we came up with to handle edge cases, calling them cello tape solutions.

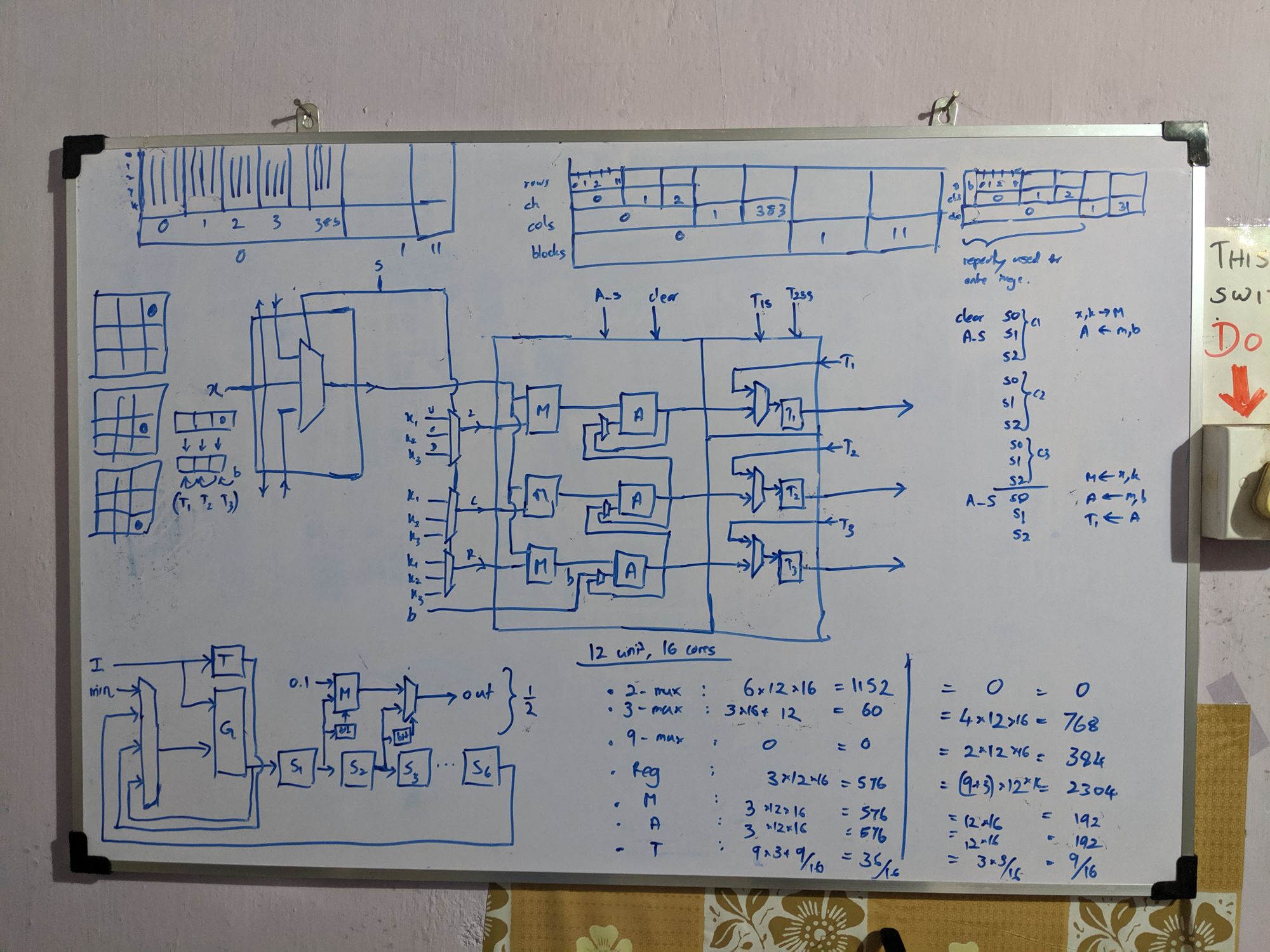
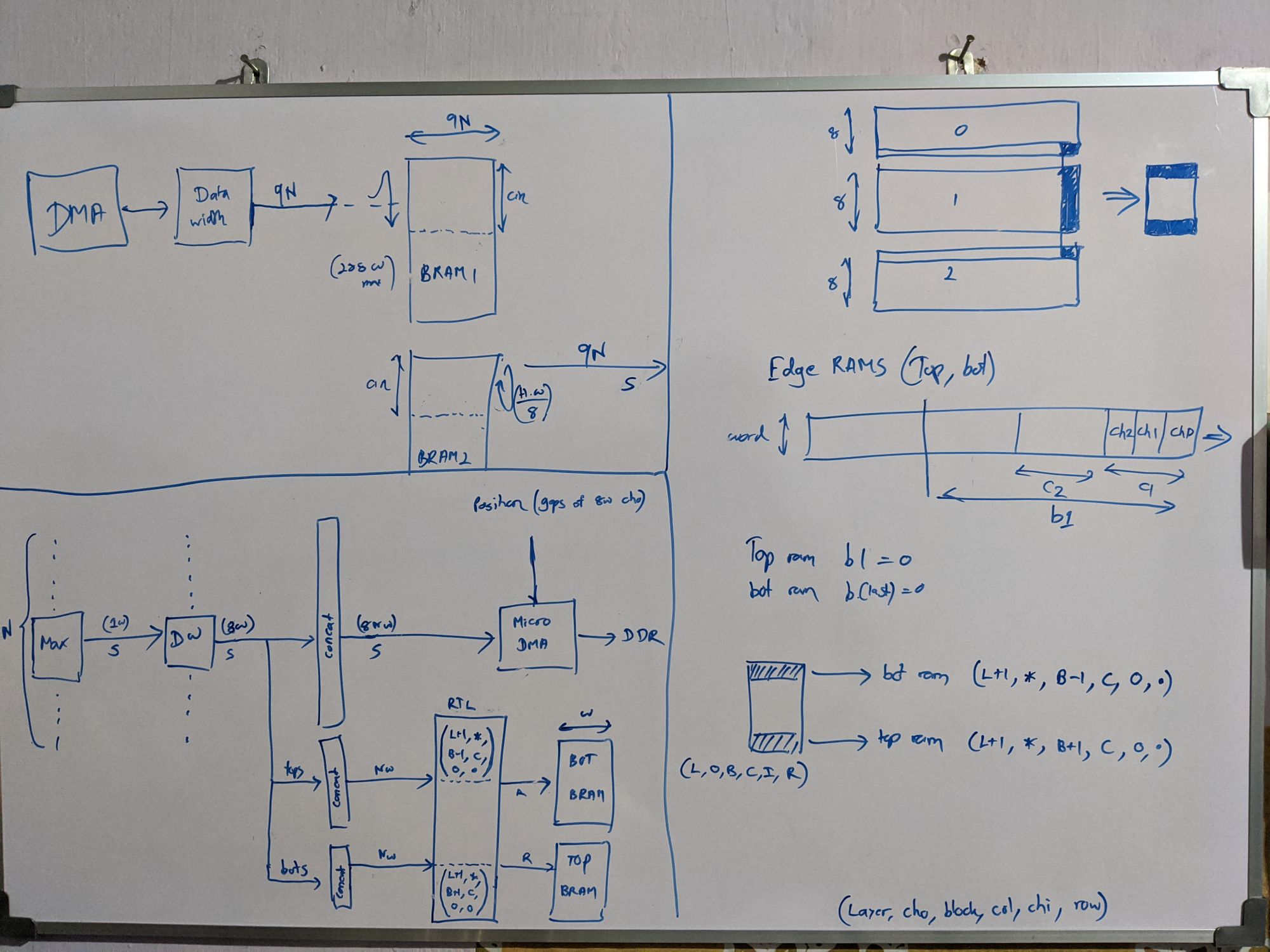
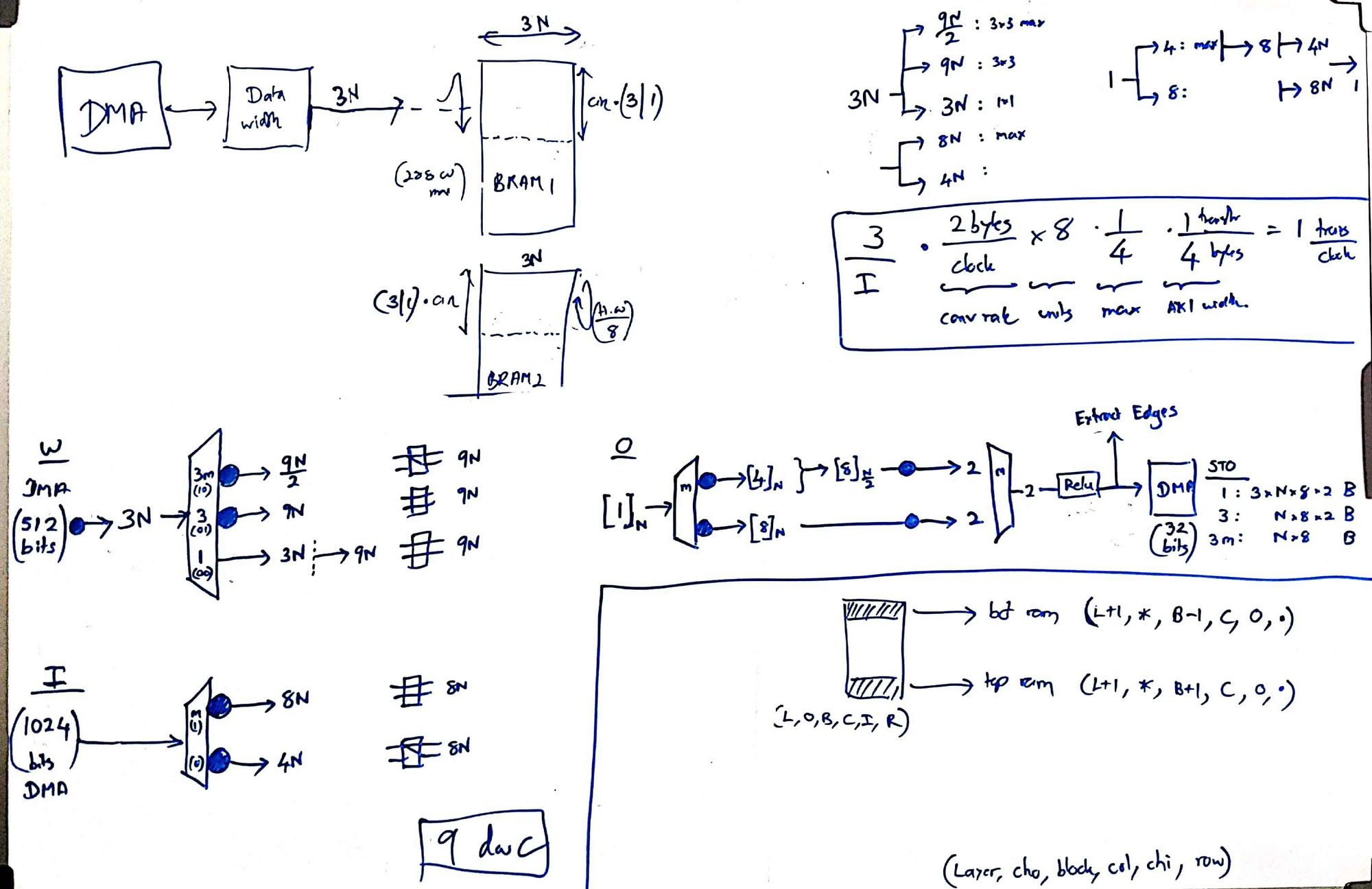
Limited by the resources and the memory bandwidth of our FPGA, I went back to the whiteboard. On an arid afternoon of August that I vividly remember, I conceived Kraken’s cornerstone. Staying in Colombo to work on this without going home for mid vacations, staring at the whiteboard and sweating in the unbearable Colombo heat, it flashed to me. That I can separate the convolution into horizontal and vertical, and shift them independently, such that partial sums snake through the 3 PEs in a core to compute a full 3x3 convolution. Within an hour, I had the accelerator design ready, with data rates and clock cycles calculated.
Rukshan hates my habit of changing the architecture, introducing new features every day, in the name of optimizing it. As he spends several weeks verifying designs without skipping a corner case, it is a nightmare when I change a verified design. Basically, I'm progressive and he's conservative, making us the ideal pair of designers. I spent a few days convincing him, showing that the core 2.0, was 4 times faster, used five times fewer 3-muxes, zero 9-muxes, about 20 times fewer registers (for the same speed), with 100% utilization of all multipliers and adders.
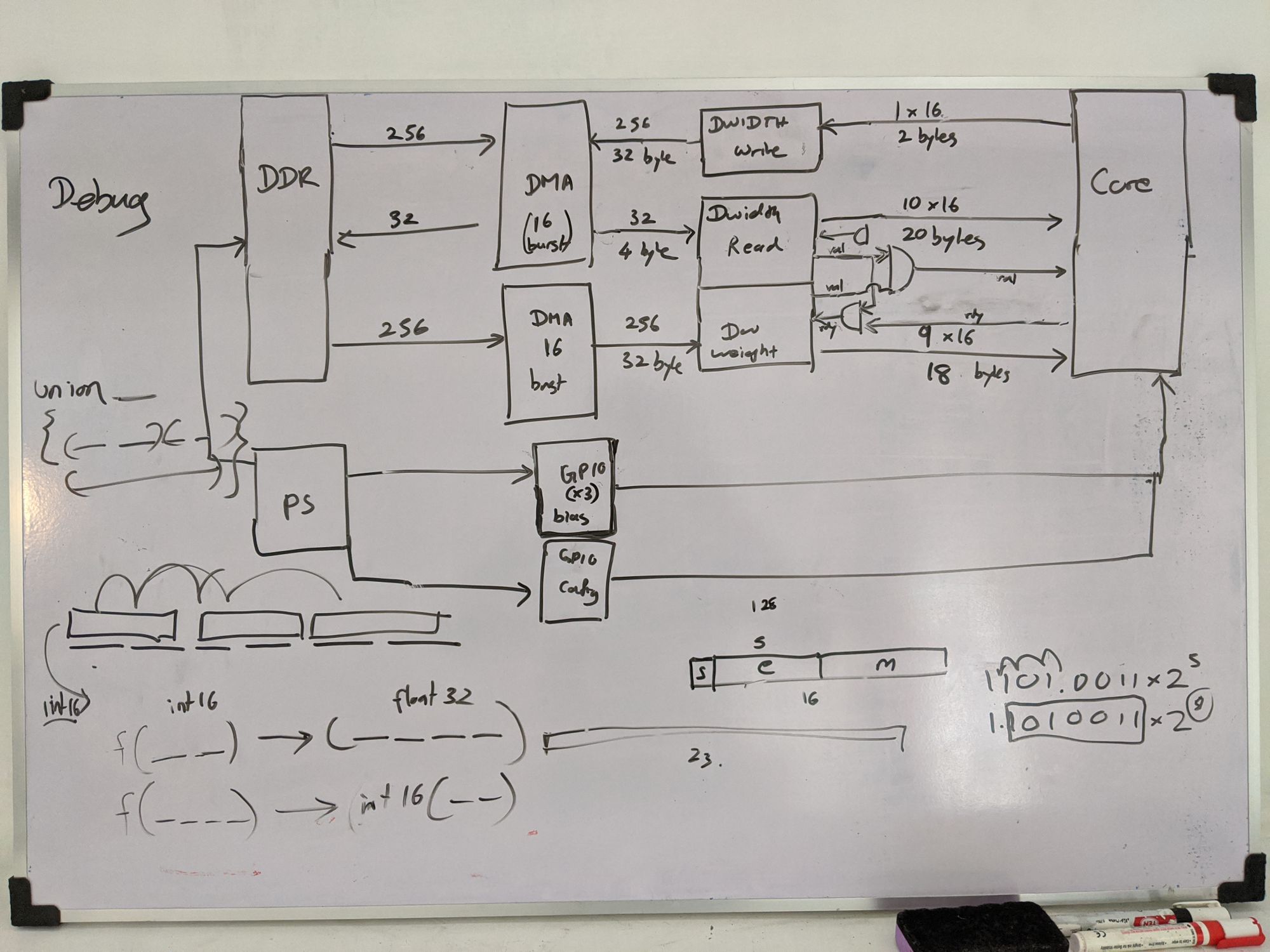
He finally came around and started implementation. I designed some support modules and implemented them, and I started working on the PS-PL (ARM-FPGA) coordination. It took me a while to wrap my head around the Vivado design flow and I finally cracked it after I got some hands-on experience at the workshop organized by International Center for Theoretical Physics, Italy in Assam, India.
Four of us stayed together at Tehara's home for a month-long sprint. The final system could run the 3x3, 1x1 layers of YOLOv2, implemented at 50 MHz on Xilinx Z706. The fmax was disappointing, and we knew why. Without any guidance in digital design, we implemented our AXI stream modules to handle the handshakes combinationally, resulting in an extremely long path from the back to the front of the pipe for the ready signal. Also, the enable signals of the nested counters of 5-levels were implemented combinationally, causing another long path. We didn't have time to redesign and verify it, so we decided to go with what we had.
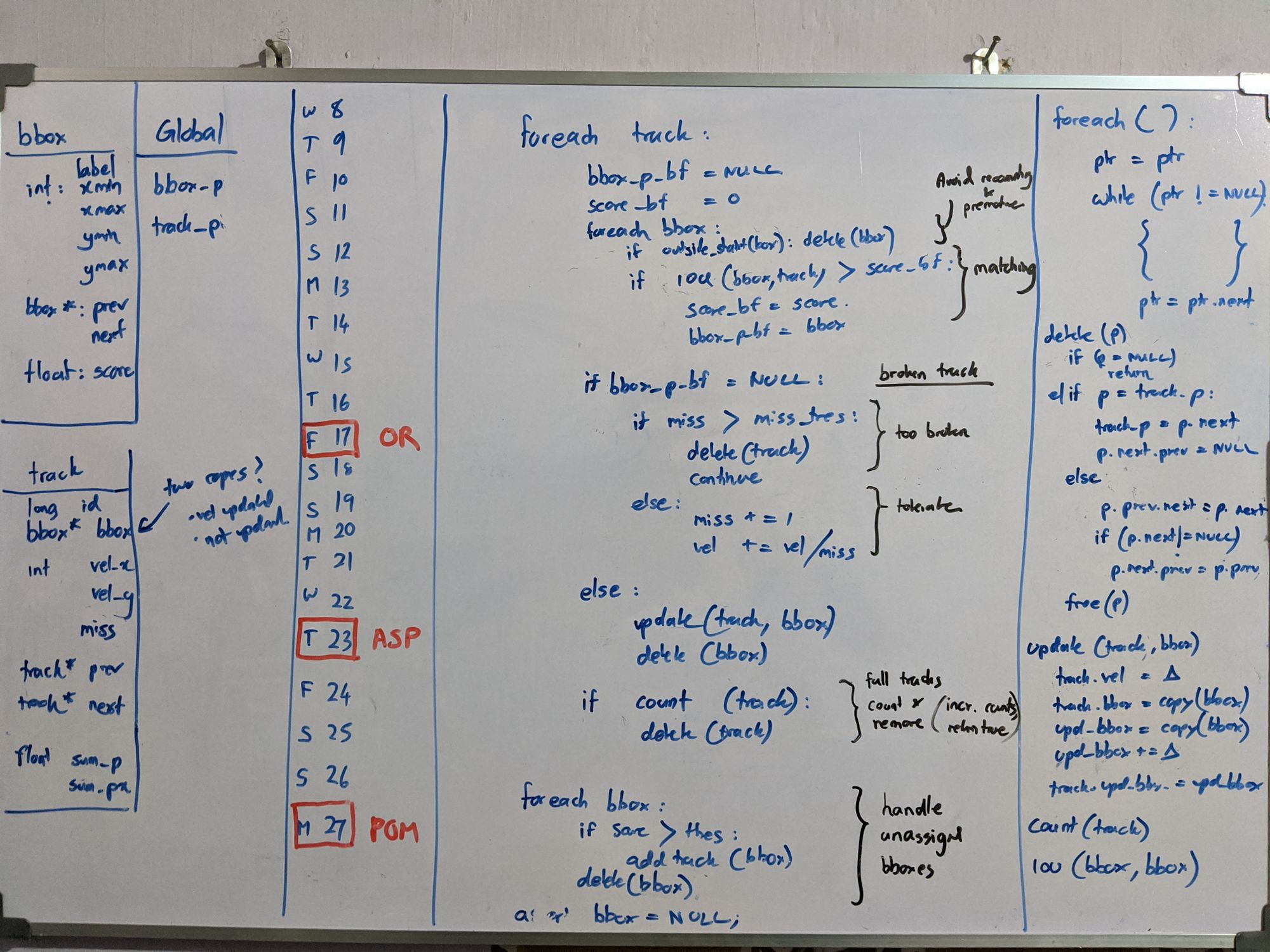
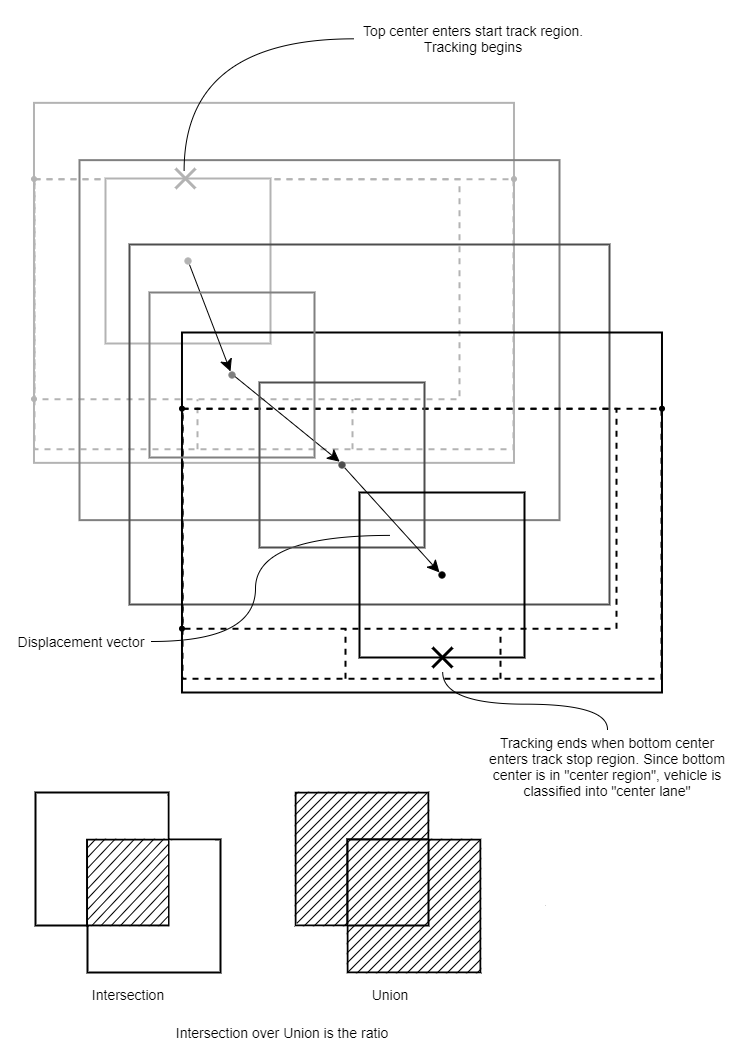
3. Tracking Algorithm (Aba)
Meanwhile, I designed a lightweight, IOU-based, standalone (no libraries) object tracking algorithm, robust to broken tracks, double-counting...etc and implemented them in both python and C (bare-metal on ARM side of ZYNQ FPGA.
- Near 97% vehicle counting accuracy in the daytime, 85% accuracy in the night, rainy time, on test data (on a road the CNN has never seen before)
- Object detector (YOLOv2) has less accuracy. But tracking algorithm is designed to obtain near 100% accuracy in vehicle counting and identification
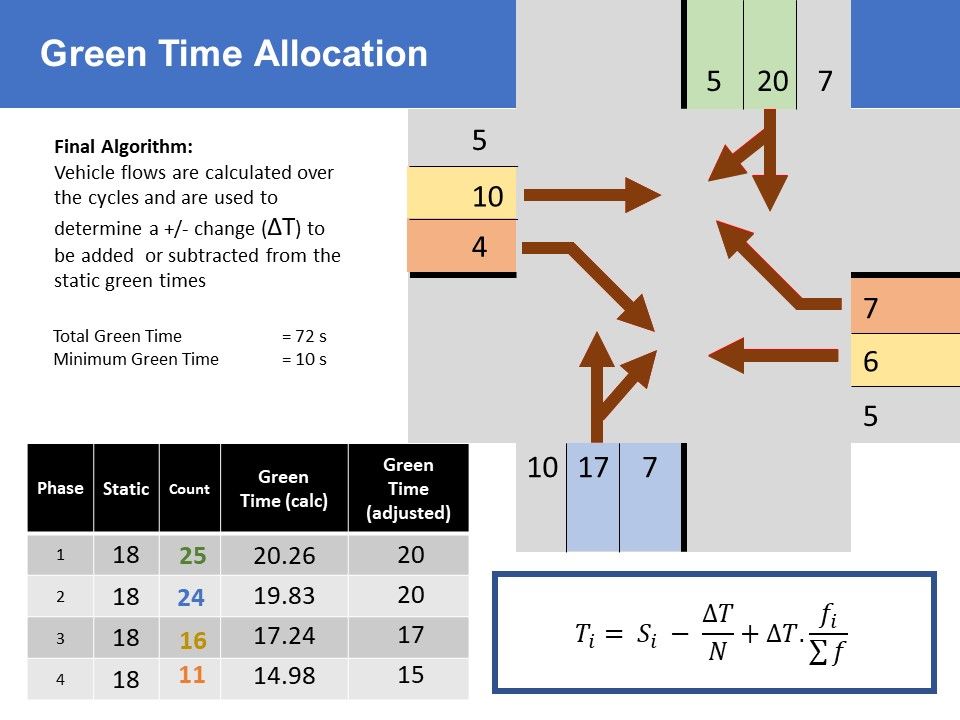
4. Delta Algorithm for Traffic timing (Aba), VISSIM verification (Chinthana)
With that, I also designed and tested 8 algorithms based on density, bounding box count, flow...etc. Chinatha figured out the VISSIM software, built a sophisticated intersection based on a real-world one, and tested the algorithms. None of them converged.
Our supervisor had suggested an algorithm, where static time is changed a little, based on the ratio of the number of vehicles, which failed to converge on testing. Thinking about it, I figured a way to put it into an equation, but with traffic flow. We named it the Delta Algorithm. During poor visibility, it naturally falls back to static timing. Chinthana tested it and found it converges. We tuned the sensitivity parameter.
Acknowledgement
We are forever indebted to our families of Tehara and Chinthana for hosting our team for weeks/months during strikes and study breaks, allowing us to work together. In addition, we thank our Supervisors: Prof. Rohan and Prof. Saman Bandara for their support and assistance.
Behind the Scenes
My team: abrutech
We stayed for months at each other's homes to work together day and night. We became a part of each other's families, celebrating birthdays, night outs... the most icon team in our batch, bonded for life! <3









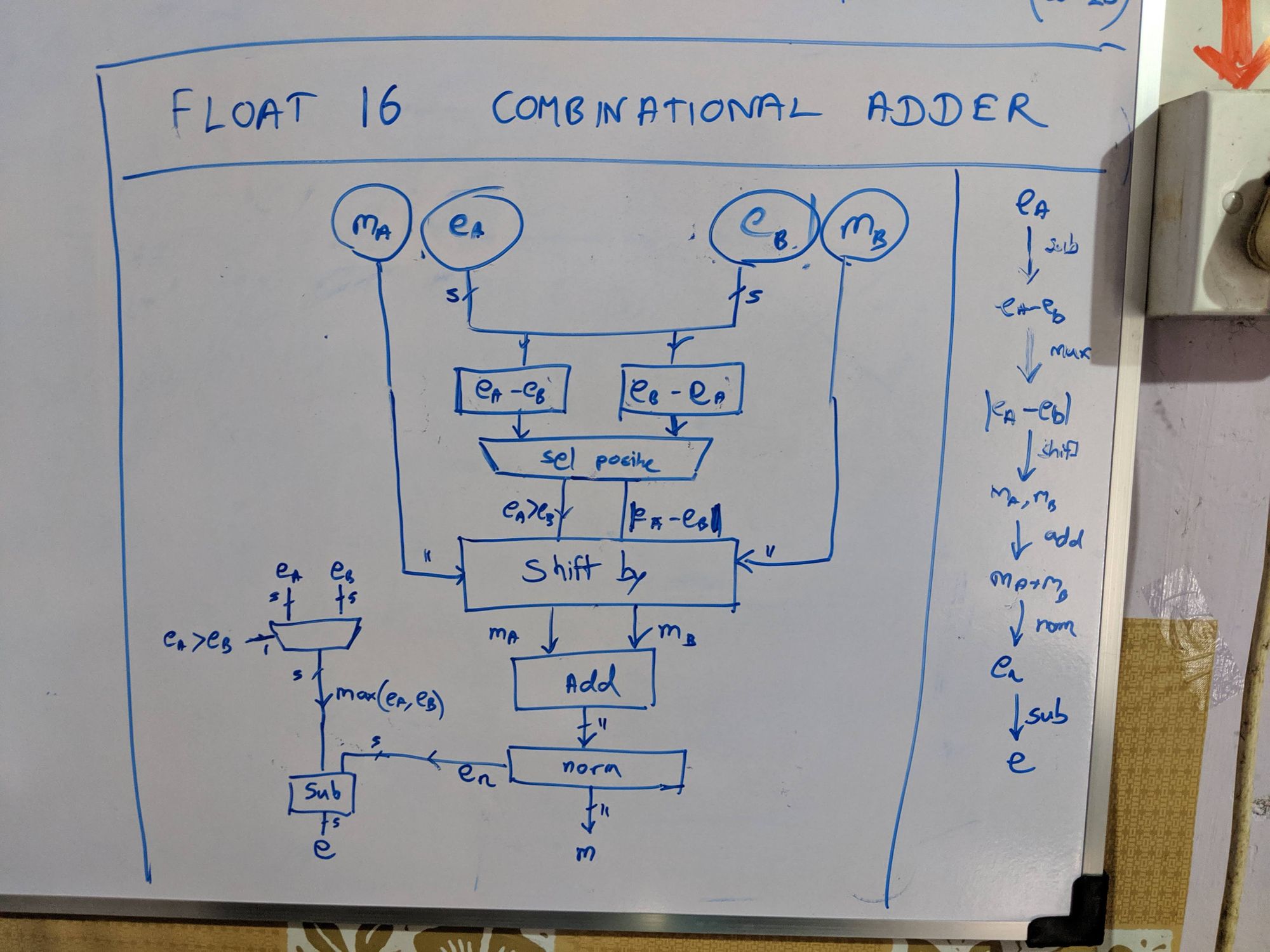
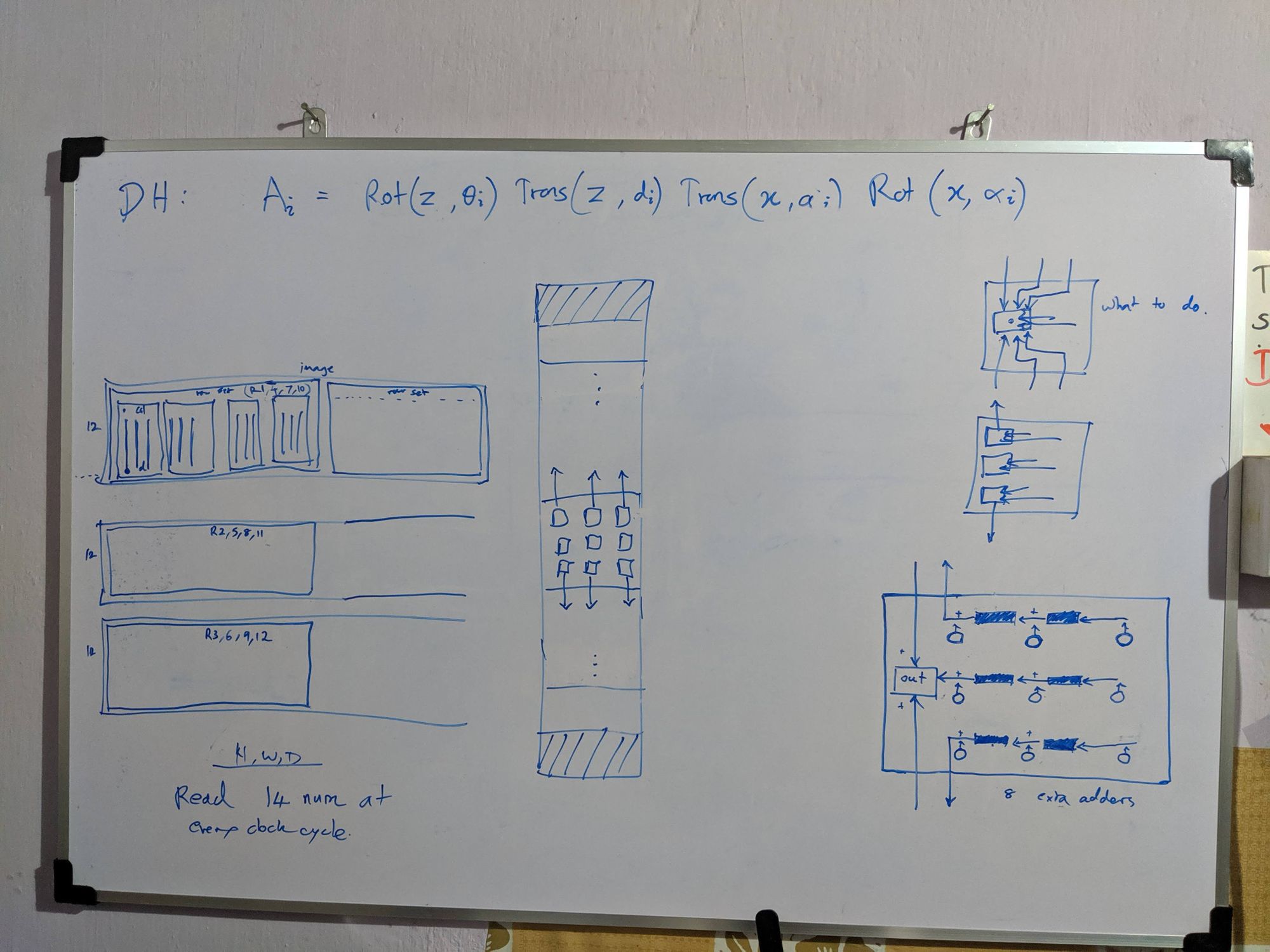
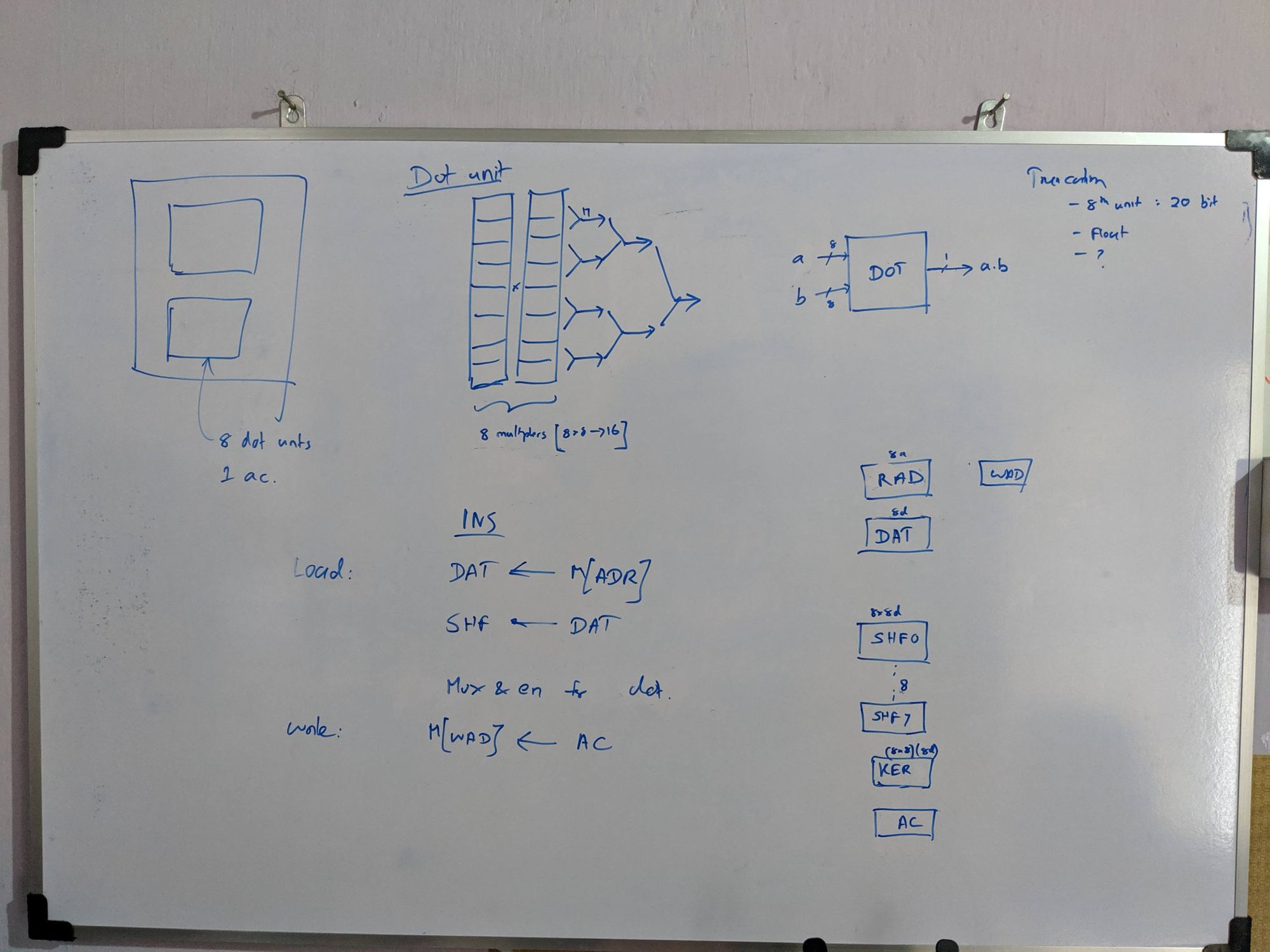
How I work
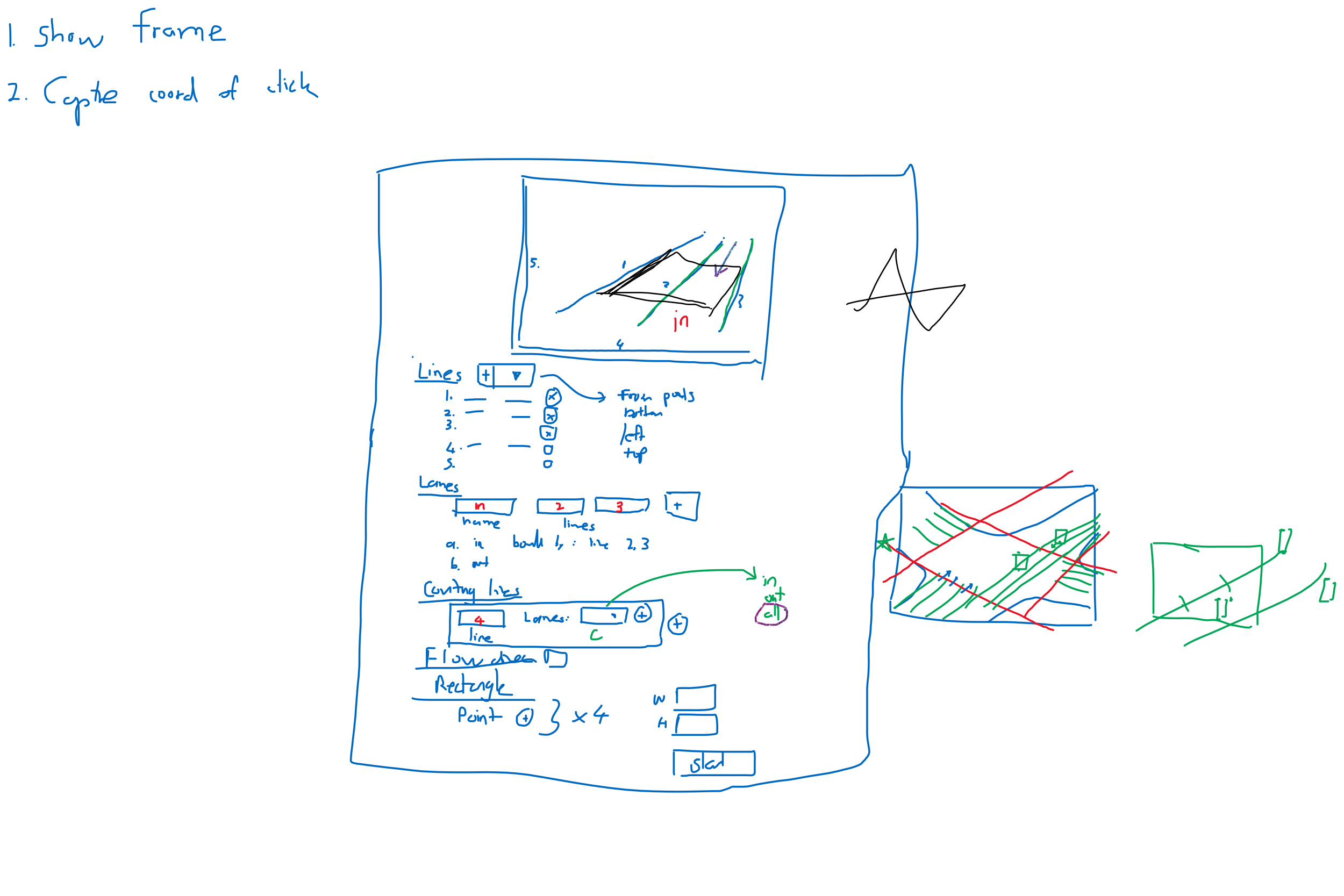
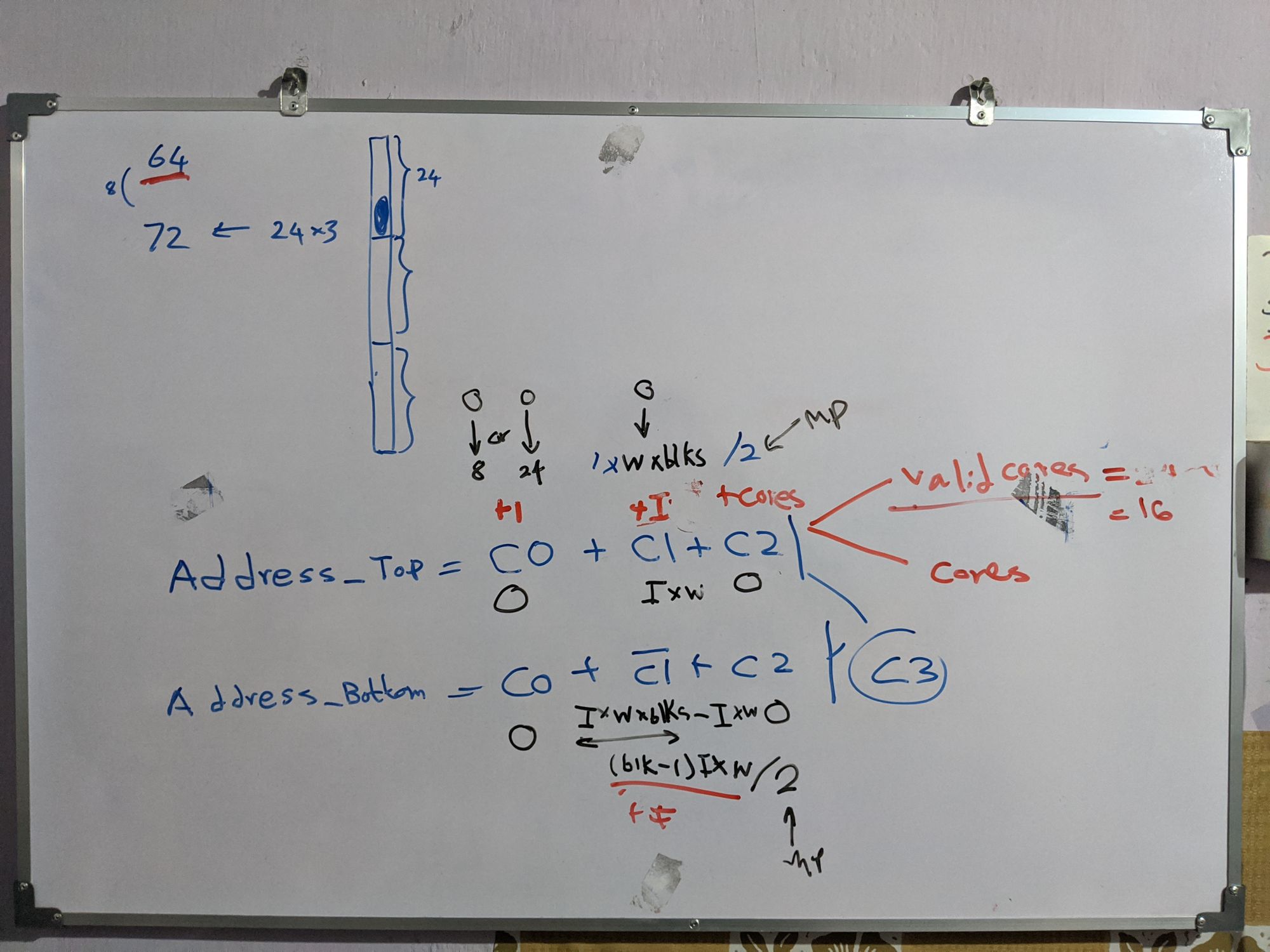
My whiteboard designs throughout the project. Some were not implemented. Just to show you how I work. :-)